Research Article
CUTEv2: 面向多样化CPU架构的统一可配置矩阵扩展
CUTEv2: 面向多样化CPU架构的统一可配置矩阵扩展
原文链接: arXiv:2604.11615 代码
摘要
矩阵扩展已成为现代CPU应对AI工作负载激增需求的关键特性。然而,现有设计往往带来显著的硬件和软件设计开销:与CPU流水线紧耦合增加了跨平台集成复杂度,细粒度同步指令阻碍了高性能内核开发。
本文提出了一种统一且可配置的CPU矩阵扩展架构CUTEv2。通过将矩阵单元与CPU流水线解耦,该设计实现了低开销集成,同时保持与现有计算和内存资源的紧密协调。可配置矩阵单元支持混合精度运算,可适应不同的计算需求和内存带宽约束。异步矩阵乘法抽象配合灵活的粒度隐藏了硬件细节,简化了矩阵-向量重叠执行,并支持统一的软件栈。
该架构已集成到四个开源CPU RTL平台(Rocket、Shuttle、BOOM、XiangShan)并进行评估。在GEMM工作负载下,矩阵单元利用率在所有平台上超过90%。当配置与Intel AMX相当的计算吞吐量和内存带宽时,该设计在ResNet、BERT和Llama3上分别实现1.57×、1.57×和2.31×的加速,其中超过30%的性能提升来自重叠的矩阵-向量执行。一个4 TOPS@2GHz的矩阵单元在14nm CMOS中仅占0.53 mm²。
 图1:CUTEv2矩阵扩展示意图,展示与向量单元的协作(来源:原文Figure 1)
图1:CUTEv2矩阵扩展示意图,展示与向量单元的协作(来源:原文Figure 1)
1. 问题定义与背景
1.1 AI工作负载的多样化需求
AI技术的快速发展推动了其在自然语言处理、计算机视觉、多模态生成和具身智能等领域的广泛部署,平台涵盖从边缘设备到数据中心。典型模型由异构特性的层组成:
- 计算密集型层:线性变换、注意力机制、卷积等,以矩阵乘法为主
- 内存密集型层:激活函数、(反)量化、归一化等逐元素操作
“AI workloads have been widely deployed across diverse computing platforms, from edge devices to data centers. Typical models consist of layers with heterogeneous characteristics.”
1.2 现有CPU矩阵扩展的局限性
Intel、Arm、IBM以及RISC-V社区已推出多种矩阵扩展:
| 扩展 | 厂商/组织 | 关键特性 |
|---|---|---|
| Intel AMX | Intel | Tile寄存器,专用矩阵单元 |
| Arm SME | Arm | 可扩展矩阵扩展,专用累加器寄存器 |
| IBM MMA | IBM | 复用向量单元数据通路 |
| RISC-V IME/VME/AME | RISC-V社区 | 多种提案,集成度各异 |
然而,现有设计存在关键挑战:
硬件集成挑战:
- 矩阵单元常与CPU流水线紧耦合
- 与向量寄存器文件或加载-存储单元密切交互
- 细粒度同步矩阵指令引入大量结构和数据冒险
- 增加集成复杂度和验证工作量
- 限制跨微架构的可移植性
软件可编程性挑战:
- AI工作负载通常将矩阵乘法与大量逐元素操作结合
- 需要矩阵和向量单元紧密协调
- 在单指令流中表达细粒度交错对程序员和编译器负担重
- 内核设计和调度复杂
2. CUTEv2架构设计
2.1 核心设计原则
CUTEv2遵循三项关键设计原则:
- 解耦集成:矩阵单元与CPU流水线解耦,避免对寄存器文件和内存路径的侵入式修改
- 可配置性:支持灵活的微架构配置,计算能力可从0.5扩展到32 TOPS
- 异步抽象:仅定义异步矩阵乘法和同步原语,形成最小统一接口
2.2 架构概览
 图2:CUTEv2与现有矩阵扩展的架构对比(来源:原文Figure 2)
图2:CUTEv2与现有矩阵扩展的架构对比(来源:原文Figure 2)
硬件特性:
- 精度支持:FP8/INT8/FP16/BF16/TF32混合精度计算
- 计算规模:0.5-32 TOPS可配置
- 内存接口:通过专用加载/存储单元访问内存层次结构
- 向量协作:与向量单元共享内存带宽,支持矩阵-向量重叠执行
ISA与编程模型:
- 异步矩阵乘法指令(非阻塞)
- 同步原语(等待矩阵操作完成)
- 灵活的粒度支持
- 隐藏硬件特定细节
2.3 计算-带宽约束模型
CUTEv2采用计算-带宽约束模型指导配置:
“The matrix unit is carefully decoupled from the CPU pipeline to avoid intrusive modifications to register files and memory paths, reducing co-design and verification complexity.”
配置公式:
- Scratchpad大小根据计算能力和内存带宽配置
- 确保矩阵单元利用率最大化
- 适应从嵌入式到高性能CPU的多样化场景
3. 核心创新
3.1 异步矩阵乘法抽象
与传统同步指令不同,CUTEv2采用异步执行模型:
优势:
- 隐藏硬件细节,简化编程
- 支持灵活的矩阵-向量重叠执行
- 改善可编程性
- 实现可移植的软件栈
编程模式:
1. 发起异步矩阵乘法
2. 执行独立的向量操作
3. 同步等待矩阵操作完成
4. 继续后续计算
3.2 矩阵-向量融合执行
AI推理中的关键优化是矩阵乘法与逐元素操作的融合:
| 模型 | 融合操作示例 |
|---|---|
| ResNet | Conv + ReLU + Quantization |
| BERT | Linear + GELU + LayerNorm |
| Llama3 | Linear + SiLU + RMSNorm + Quantization |
“Overlapped matrix–vector execution contributes 66.7%, 50.9%, and 33.6% of the performance gain on three workloads.”
CUTEv2的异步抽象使这种融合更容易实现,显著提升性能。
3.3 跨平台可移植性
CUTEv2已集成到四个开源CPU RTL平台:
| 平台 | 类型 | 特性 |
|---|---|---|
| Rocket | 顺序单发射 | 基础RISC-V核心 |
| Shuttle | 顺序超标量 | 基于Rocket的超标量设计 |
| BOOM | 乱序执行 | Berkeley乱序机 |
| XiangShan | 高性能乱序 | 中科院高性能RISC-V处理器 |
4. 实验评估
4.1 实验设置
对比平台: | 平台 | 矩阵扩展 | 峰值性能 | 内存带宽 | |—–|———|———|———| | Intel Xeon 8580 | AMX | 4 TOPS@8-bit | ~100 GB/s | | IBM S1022 | MMA | 2 TOPS@8-bit | ~50 GB/s | | Apple M4 | SME | 4 TOPS@8-bit | ~100 GB/s | | Ours (Shuttle) | CUTEv2 | 4 TOPS@8-bit | 48 GB/s |
工作负载:
- GEMM(通用矩阵乘法)
- ResNet-50(图像分类)
- BERT-base(自然语言理解)
- Llama3.2-1B(大语言模型)
4.2 GEMM性能
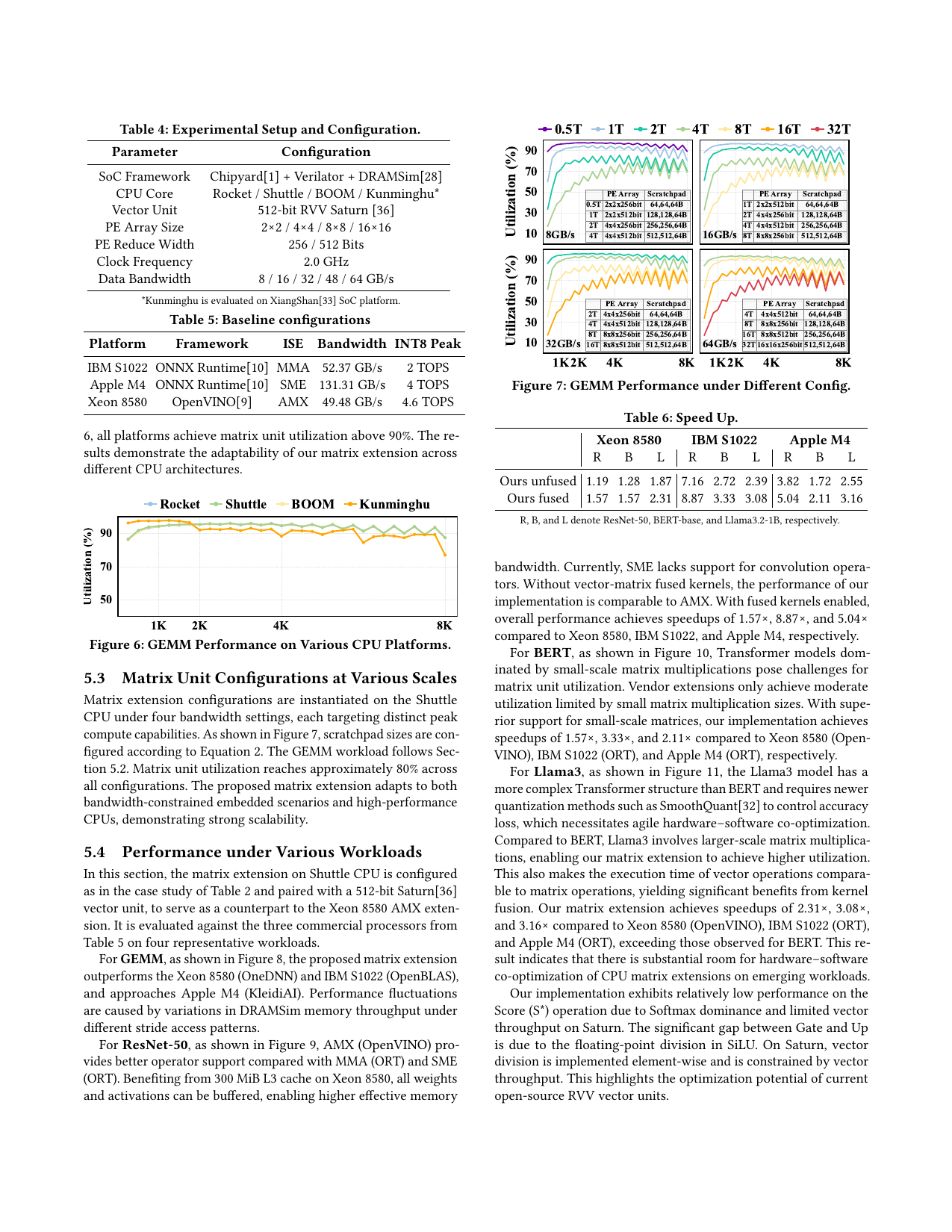 图3:CUTEv2与现有商业扩展的GEMM性能对比(来源:原文Figure 8)
图3:CUTEv2与现有商业扩展的GEMM性能对比(来源:原文Figure 8)
矩阵单元在所有集成平台上GEMM利用率超过90%。与商业扩展相比:
- 优于Xeon 8580(OneDNN)和IBM S1022(OpenBLAS)
- 接近Apple M4(KleidiAI)
4.3 AI模型推理性能
ResNet-50
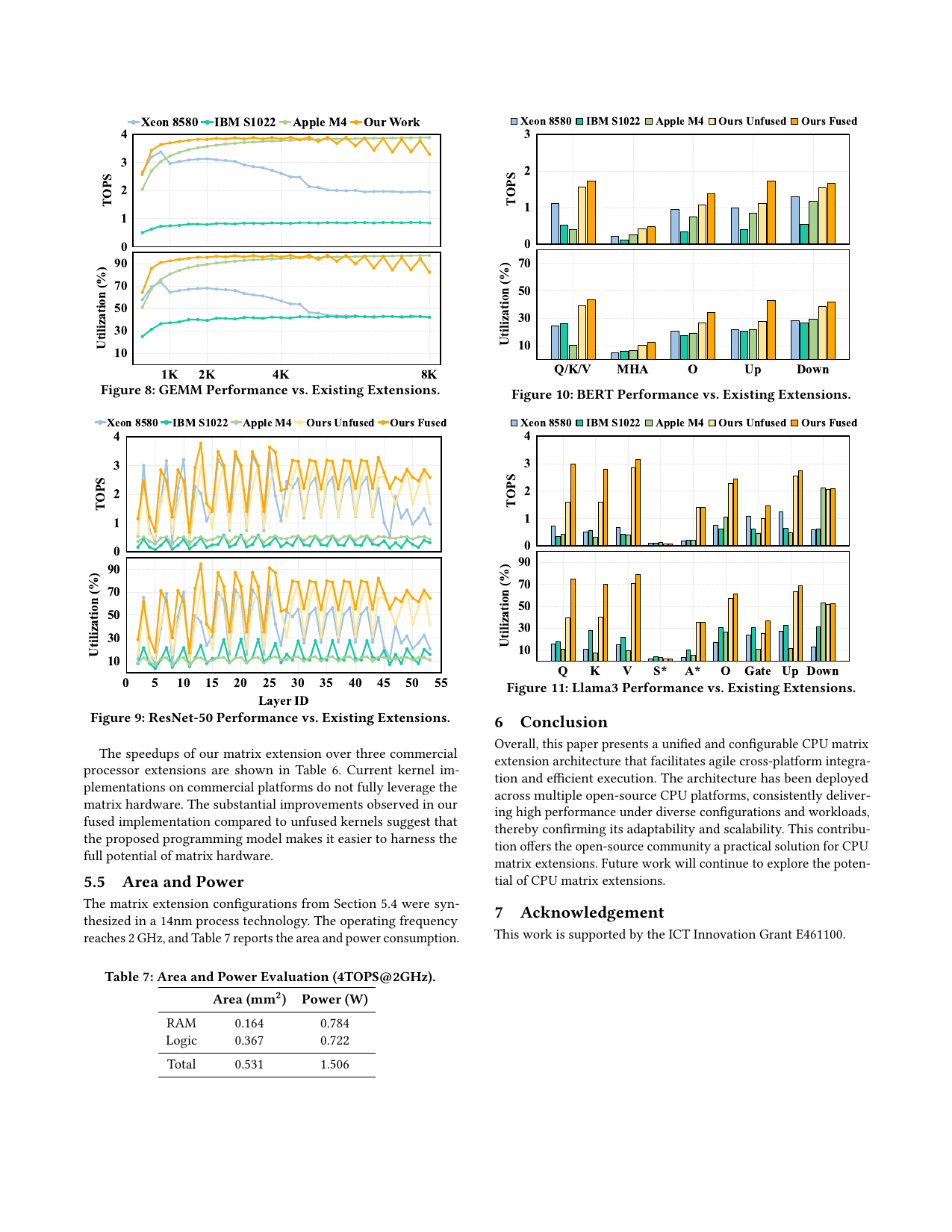 图4:ResNet-50推理性能对比(来源:原文Figure 9)
图4:ResNet-50推理性能对比(来源:原文Figure 9)
| 实现 | 相对性能 |
|---|---|
| Xeon 8580 (AMX/OpenVINO) | 1.0× (baseline) |
| IBM S1022 (MMA/ORT) | 0.13× |
| Apple M4 (SME/ORT) | 0.31× |
| Ours (unfused) | 1.19× |
| Ours (fused) | 1.57× |
关键观察:
- Xeon 8580的300 MiB L3缓存可缓存所有权重和激活
- SME目前缺乏卷积算子支持
- 融合内核带来显著性能提升
BERT
图5:BERT推理性能对比(来源:原文Figure 10)
Transformer模型以小规模矩阵乘法为主,对矩阵单元利用率构成挑战:
| 实现 | 相对性能 |
|---|---|
| Xeon 8580 (AMX/OpenVINO) | 1.0× (baseline) |
| IBM S1022 (MMA/ORT) | 0.47× |
| Apple M4 (SME/ORT) | 0.74× |
| Ours (unfused) | 1.28× |
| Ours (fused) | 1.57× |
关键观察:
- 商业扩展受限于小规模矩阵的利用率
- CUTEv2对小规模矩阵的优越支持带来显著优势
Llama3
 图6:Llama3推理性能对比(来源:原文Figure 11)
图6:Llama3推理性能对比(来源:原文Figure 11)
Llama3比BERT具有更复杂的Transformer结构:
| 实现 | 相对性能 |
|---|---|
| Xeon 8580 (AMX/OpenVINO) | 1.0× (baseline) |
| IBM S1022 (MMA/ORT) | 0.75× |
| Apple M4 (SME/ORT) | 0.73× |
| Ours (unfused) | 1.87× |
| Ours (fused) | 2.31× |
关键观察:
- Llama3涉及更大规模的矩阵乘法,矩阵单元利用率更高
- 向量操作执行时间与矩阵操作相当,融合收益显著
- 表明新兴工作负载上CPU矩阵扩展的硬件-软件协同优化潜力巨大
4.4 性能提升分解
| 模型 | 总加速 | 融合贡献 |
|---|---|---|
| ResNet-50 | 1.57× | 66.7% |
| BERT | 1.57× | 50.9% |
| Llama3 | 2.31× | 33.6% |
4.5 面积与功耗
在14nm工艺下,4 TOPS@2GHz配置的评估结果:
| 组件 | 面积 (mm²) | 功耗 (W) |
|---|---|---|
| RAM | 0.164 | 0.784 |
| Logic | 0.367 | 0.722 |
| Total | 0.531 | 1.506 |
关键指标:
- 面积效率:7.53 TOPS/mm²
- 能效:2.66 TOPS/W
4.6 可扩展性
图7:不同规模配置下的矩阵单元利用率(来源:原文Figure 7)
在四种内存带宽设置下,矩阵单元配置从0.5到32 TOPS:
- 所有配置下GEMM利用率约80%
- 适应从嵌入式到高性能CPU的多样化场景
- 展示强可扩展性
5. 与商业扩展的深度对比
5.1 架构设计对比
| 特性 | Intel AMX | Arm SME | IBM MMA | CUTEv2 |
|---|---|---|---|---|
| 寄存器架构 | Tile寄存器 | 专用累加器 | 复用向量寄存器 | 异步指令 |
| 执行模型 | 同步 | 同步 | 同步 | 异步 |
| 与CPU关系 | 解耦 | 解耦 | 紧耦合 | 解耦 |
| 精度支持 | INT8/FP16/BF16 | INT8/FP16/BF16 | INT8/FP16 | FP8/INT8/FP16/BF16/TF32 |
| 可配置性 | 固定 | 固定 | 固定 | 0.5-32 TOPS |
| 开源 | 否 | 否 | 否 | 是 |
5.2 软件生态对比
| 平台 | 矩阵库 | 框架支持 |
|---|---|---|
| Intel | oneDNN, OpenVINO | PyTorch, TensorFlow |
| Arm | KleidiAI | PyTorch, TensorFlow |
| IBM | OpenBLAS, ORT | ONNX Runtime |
| CUTEv2 | 自定义高性能内核 | 可移植软件栈 |
6. 优点与局限
6.1 主要优点
- 低开销集成:与CPU流水线解耦,减少协同设计和验证复杂度
- 跨平台可移植性:已在四个开源CPU平台验证
- 高性能:在ResNet、BERT、Llama3上超越商业扩展
- 矩阵-向量融合:异步抽象简化重叠执行编程
- 灵活可配置:计算能力0.5-32 TOPS,适应多样化场景
- 混合精度:支持FP8到TF32多种精度
- 开源:RTL实现和高性能内核完全开源
6.2 局限与未来工作
- 软件生态成熟度:相比oneDNN、KleidiAI等商业库,软件生态仍在建设中
- 算子支持:当前实现聚焦核心算子,完整算子覆盖需要持续开发
- 量化方法:Llama3需要SmoothQuant等新量化方法控制精度损失
- 向量单元瓶颈:某些操作(如Softmax、SiLU中的除法)受限于向量单元吞吐量
7. 总结
CUTEv2提出了一种统一且可配置的CPU矩阵扩展架构,实现了敏捷的跨平台集成和高效执行。关键贡献包括:
- 架构创新:解耦设计降低集成开销,可配置性适应多样化需求
- 硬件-软件协同:异步抽象简化编程,矩阵-向量融合显著提升性能
- 开源实现:在四个开源CPU平台完整实现并验证
实验结果表明,CUTEv2在GEMM利用率(>90%)和AI模型推理性能(ResNet 1.57×、BERT 1.57×、Llama3 2.31×)上均优于或接近商业扩展,同时保持极小的面积开销(0.53 mm²@4 TOPS)。
这项工作为开源社区提供了实用的CPU矩阵扩展解决方案,展示了开源硬件在AI加速器领域追赶甚至超越商业方案的