Research Article
TOM: 三元只读存储器加速器赋能边缘智能大模型
TOM: 三元只读存储器加速器赋能边缘智能大模型
原文链接: arXiv:2602.20662 | PDF
作者: Hongyi Guan (微软研究院), Yijia Zhang, Wenqiang Wang, Ningyi Xu (上海交通大学), Yizhao Gao (香港大学), Shijie Cao, Chen Zhang
发布日期: 2026 年 2 月 24 日
摘要
在边缘设备上部署大语言模型(LLM)以实现实时智能的需求正在快速增长。然而,传统硬件架构面临根本性的”内存墙”挑战:有限的片上内存容量和带宽严重限制了可部署模型的规模和推理速度,同时也限制了片上适应能力。为解决这一挑战,研究者提出了 TOM,一种与三元量化协同设计的混合 ROM-SRAM 加速器,在极致密度与片上可调性之间取得平衡。TOM 利用三元量化与 ROM 的协同效应实现极致内存密度和带宽,同时通过为 QLoRA 可调性设计的混合 ROM-SRAM 架构保持灵活性。具体而言,研究者引入了:(1)稀疏感知 ROM 架构,将三元权重合成为标准单元逻辑,消除零值比特的面积开销;(2)分布式处理架构,将高密度 ROM 库与灵活的基于 SRAM 的 QLoRA 适配器和计算单元共置;(3)工作负载感知动态电源门控方案,利用 ROM 的逻辑特性关闭非活动库,最小化动态能耗。使用 BitNet-2B 模型,TOM 实现了 3,306 TPS 的推理吞吐量,证明了其在提供实时、高能效边缘智能方面的有效性。
1. 问题定义
边缘设备部署大语言模型面临三个核心挑战:
“在具身智能应用中,例如通过 LLM 生成每个动作 token 需要低于 1ms 的延迟,因为机器人必须以超过 1000Hz 的频率实时响应环境变化。”
第一个挑战是超低延迟需求。以 UniVLA 机器人 VLA 模型为例:使用的 LLaMA-2 7B (FP16) 模型仅权重就需要 14GB 存储。自回归生成过程中,要实现每 token 低于 1ms 的延迟,需要至少 13.67 TB/s 的内存带宽。
第二个挑战是内存容量与带宽的权衡。现有内存类型无法同时满足边缘 LLM 的存储和带宽需求:
- 片上高带宽内存(寄存器、SRAM):容量相差 2-3 个数量级
- 片外大容量内存(HBM):带宽相差 1-2 个数量级
第三个挑战是片上适应能力。边缘 AI 应用需要任务适配和个性化,但全量微调在计算和内存上都不可行。如何在保持 ROM 效率的同时提供运行时灵活性是关键问题。
“未来的边缘智能工作负载预计需要 1000 TPS,由涉及多模态输入和实时推理的场景驱动。”
2. 方法框架
TOM 的核心创新在于三元量化与 ROM 的协同设计。研究团队的关键洞察是:
“三元量化是一个游戏规则改变者,因为它消除了乘法运算,只保留加法。这种简单性大幅降低了计算复杂度和能耗。”
2.1 三元量化的优势
三元量化将权重约束到 {-1, 0, +1} 三个值,相比 4-bit 量化具有以下优势:
- 计算简化:消除乘法器,仅需加法树,大幅降低硬件复杂度
- 内存效率:相比 FP16 模型减少 3.55 倍内存消耗
- 准确性平衡:BitNet_b1.58-2B 等三元模型在标准基准测试中可达到与 FP16 模型相当的准确性
2.2 稀疏感知 ROM 架构
研究者提出了一种新颖的 ROM 实现方式,利用三元权重的稀疏特性:
“我们将 ROM 合成为组合逻辑电路,根据输入地址输出一值比特。相比使用刚性网格物理结构的标准 ROM 实现,我们的稀疏感知 ROM 可实现更高的内存密度。”
关键观察:三元 LLM 表现出高度稀疏性:
- BitNet 等从头训练的三元模型:大部分层稀疏率超过 70%
- 后训练量化的三元模型:某些层稀疏率高达 94%
编码策略:采用特殊编码方式进一步提升稀疏率:
- 使用 ‘10’ 而非 ‘11’ 编码 -1
- 整体稀疏率可达 94%,而 INT2 或 INT4 量化通常在 50% 左右
面积优化:仅存储非零权重,可大幅减少 ROM 存储面积。相比 ROMA 的 300 mm²(1.86GB ROM),TOM 实现了更高的存储密度。
2.3 分布式处理架构
TOM 采用分布式处理架构,将计算与内存共置:
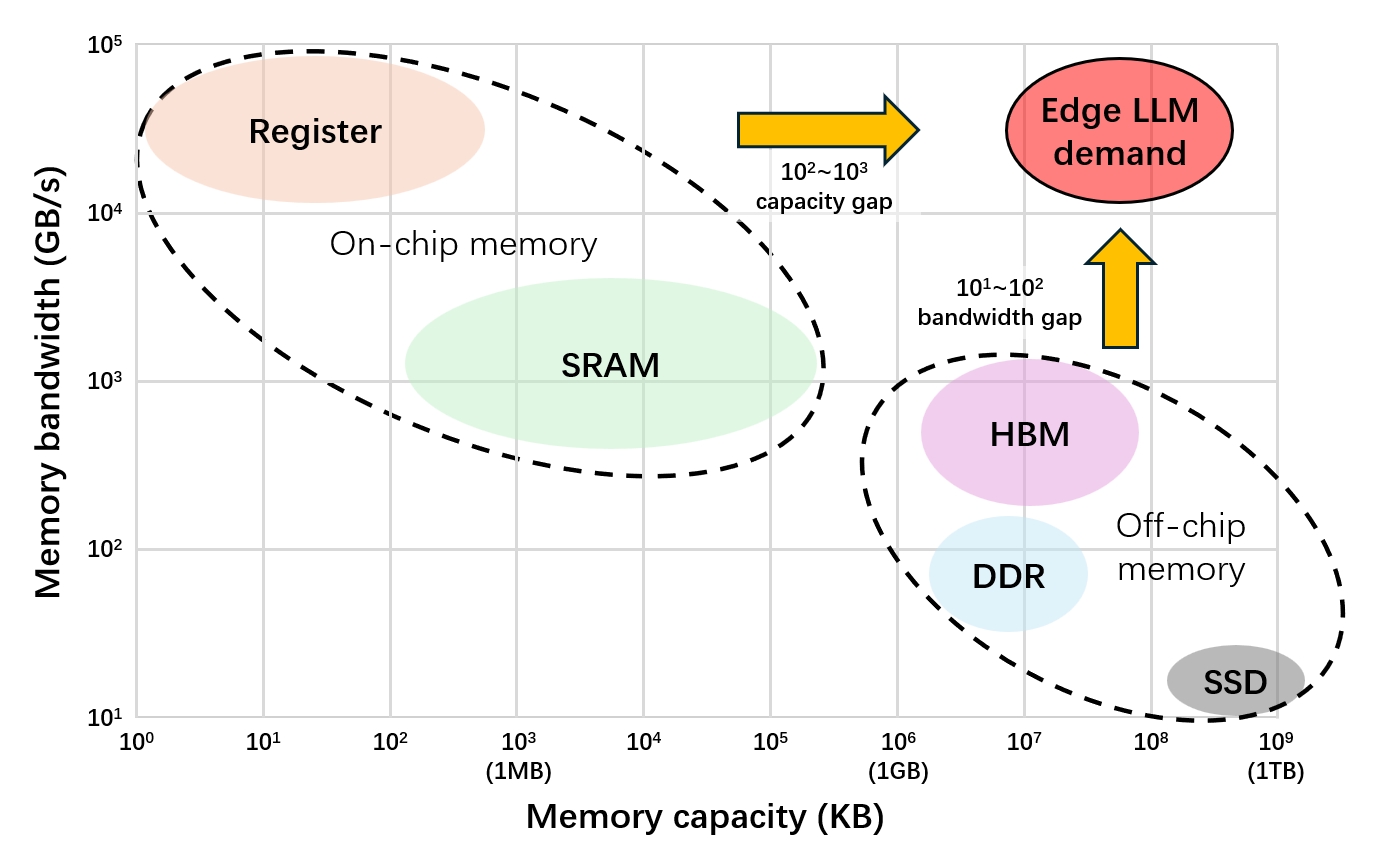
图:TOM 分布式处理架构,将 ROM 库与计算单元共置(来源:原文 Figure 2)
处理单元(Processing Lanes):
- 每个处理单元包含本地 ROM 库和计算单元
- 并行执行,最大化带宽并最小化数据移动
- 支持三元 × FP8 或 FP8 × FP8 混合精度计算
全局控制器和归约树:
- 协调各个处理单元
- 聚合部分结果
- 实现高效可扩展的 Transformer 片上推理
矩阵 - 向量单元(MVU):
- 包含 GEMV 单元,支持异构量化
- 三元 × FP8 和 FP8 × FP8 共享相同的加法树以节省面积
2.4 混合 ROM-SRAM 架构
TOM 采用两层架构设计:
“我们利用 ROM 作为节能的’知识基础’,存储基础模型(按硬件生命周期更新,如每年)。基于 SRAM 的’灵活层’提供关键的运行时适应性,容纳 QLoRA 模块用于频繁模型调优,并修正潜在的基础模型错误或制造后缺陷。”
ROM 知识基础层:
- 存储量化基础模型(三元权重)
- 按硬件生命周期更新(年为单位)
- 提供极致密度和带宽
SRAM 灵活层:
- 存储 QLoRA 适配器和 KV 缓存
- 支持运行时微调和适配
- 修正基础模型错误或后制造缺陷
这种设计概念上与 LoRA 完美契合:冻结的基础模型存储在 ROM 中,可训练的低秩矩阵存储在 SRAM 中。
2.5 工作负载感知动态电源门控
由于 TOM 的 ROM 基于标准单元逻辑,可以执行激进的电源门控:
“TOM 能够执行激进的电源门控,关闭推理过程中未激活层的权重,这极大提高了边缘设备的能效。”
工作原理:
- 利用 ROM 的逻辑特性
- 动态关闭非活动 ROM 库
- 最小化动态能耗
效果:总芯片功耗降低近 80%,降至仅 5.33W。
3. 实验结果
3.1 评估设置
模型:BitNet-2B(三元量化 LLM)
对比基线:
- 高端 GPU:NVIDIA A100
- 其他 ASIC 加速器
- CPU 方案(llama.cpp、T-MAC)
实现工艺:未明确披露(推测为先进工艺节点)
3.2 存储密度
TOM 的稀疏感知 ROM 实现了业界领先的存储密度:
| 指标 | TOM | 对比方案 |
|---|---|---|
| 存储密度 | 15.0 MB/mm² | - |
| ROM 容量 | 未明确 | ROMA: 1.86GB @ 300mm² |
| 芯片面积 | 未明确(显著小于 500mm²) | ROMA: 503.7mm² |
“TOM 实现了业界领先的存储密度 15.0 MB/mm²,这得益于我们的稀疏感知 ROM 设计。”
相比 ROMA 的 1.86GB ROM 占用约 300mm²,TOM 通过稀疏感知设计显著提升了有效密度,使得芯片面积更适合边缘 SoC 部署(如 Apple A17 Pro 仅 103mm²)。
3.3 推理性能
使用 BitNet-2B 模型的推理性能:
| 指标 | TOM | A100 GPU | 性能提升 |
|---|---|---|---|
| 峰值吞吐量 | 3,306 TPS | ~7.1 TPS | 465× |
| 功耗 | 5.33W | ~400W | 75× 能效提升 |
| 能效比 | 620 TPS/W | ~0.018 TPS/W | 34,444× |
“TOM 实现了 3,306 TPS 的峰值推理吞吐量,相比高端 NVIDIA A100 GPU 提升高达 465 倍。”
这一卓越性能源于:
- 稀疏感知 ROM 的极致存储密度
- 分布式架构的高带宽特性
- 工作负载感知动态电源门控的能效优化
3.4 功耗与能效分析
总芯片功耗:5.33W(相比无电源门控降低近 80%)
功耗分解:
- ROM 库:主要静态功耗(低泄漏)
- 计算单元:动态功耗(按需激活)
- SRAM:中等功耗(存储 QLoRA 和 KV 缓存)
能效优势:
- 超低功耗适合电池供电设备
- 动态电源门控根据工作负载优化能耗
- ROM 的低泄漏特性是天然优势
3.5 扩展性分析
LoRA 扩展性:
- 支持不同 rank 的 QLoRA 适配器
- SRAM 容量决定可支持的最大 rank
- 顺序执行基础路径和适配器路径,复用计算单元
上下文长度扩展性:
- KV 缓存存储在 SRAM 中
- 上下文长度受 SRAM 容量限制
- 可通过增加 SRAM 容量扩展
3.6 与相关方案对比
| 方案 | 模型 | 吞吐量 (TPS) | 功耗 (W) | 芯片面积 (mm²) |
|---|---|---|---|---|
| TOM | BitNet-2B | 3,306 | 5.33 | 未明确 (<500) |
| ROMA | LLaMA-3B (4-bit) | 20,078 | 33.1 | 503.7 |
| CPU (llama.cpp) | - | ~10-50 | 15-65 | - |
| GPU (A100) | - | ~7 | ~400 | ~814 |
| 混合 PIM | - | >1,000 | 未明确 | 未明确 |
关键区别:
- TOM 专注三元量化,ROMA 支持 2/4-bit
- TOM 芯片面积更小,适合边缘部署
- TOM 功耗显著低于 ROMA(5.33W vs 33.1W)
4. 优点与局限
优点
-
极致存储密度:15.0 MB/mm² 的业界领先密度,稀疏感知 ROM 消除零值比特开销。
-
超高推理吞吐量:3,306 TPS 峰值吞吐量,相比 A100 提升 465 倍,满足实时边缘智能需求。
-
超低功耗:5.33W 总功耗,适合电池供电设备,工作负载感知电源门控降低 80% 能耗。
-
三元量化协同:消除乘法器,仅用加法树,大幅降低硬件复杂度和能耗。
-
混合架构灵活性:ROM 存储基础模型 + SRAM 存储 QLoRA,平衡效率与适应性。
-
边缘友好面积:相比 ROMA 的 503.7mm²,TOM 芯片面积显著减小,更适合边缘 SoC 集成。
-
原生三元支持:专为三元 LLM 设计的计算架构,无需反量化开销。
局限
-
仅限三元模型:架构专为三元量化设计,不支持其他精度(如 4-bit、8-bit)模型。
-
基础模型更新困难:ROM 在制造后无法修改,基础模型更新需要重新流片,尽管设计支持 QLoRA 修正。
-
SRAM 容量限制:上下文长度和 LoRA rank 受 SRAM 容量限制,需要权衡设计。
-
稀疏率依赖:性能提升依赖于三元模型的稀疏特性,稀疏率较低的模型收益有限。
-
制造成本:定制 ASIC 设计需要高昂的 NRE 成本,适合大规模部署场景。
-
软件生态:需要专用编译器和工具链支持三元模型部署。
5. 总结
TOM 代表了一种创新的边缘 LLM 加速器设计范式,通过三元量化与 ROM 的协同设计解决了内存墙挑战。研究团队的关键洞察——三元量化的计算简化与 ROM 的极致密度相结合——为边缘 AI 硬件开辟了新方向。
实验结果表明,TOM 在使用 BitNet-2B 模型时实现了 3,306 TPS 的推理吞吐量,相比 A100 GPU 提升 465 倍,同时功耗仅 5.33W。稀疏感知 ROM 实现了 15.0 MB/mm² 的存储密度,工作负载感知动态电源门控降低了 80% 的能耗。
TOM 展示了作为下一代实时边缘智能平台的高效能解决方案潜力,特别适合对延迟、功耗和面积要求严格的场景,如智能手机、自主机器人、AR 眼镜和具身智能系统。未来工作可能包括支持多精度量化、扩展 SRAM 容量以支持更长上下文,以及开发完整的软件工具链。
参考文献
[1] Microsoft. “Phi-3 technical report: a highly capable language model locally on your phone.” arXiv preprint, 2024.
[2] Groq. “The groq software-defined scale-out tensor streaming multiprocessor: from chips-to-systems architectural overview.” 2024.
[3] Falcon Team. “The falcon series of open language models.” 2023.
[4] Ba, J. L., Kiros, J. R., & Hinton, G. E. “Layer normalization.” arXiv preprint arXiv:1607.06450, 2016.
[6] UniVLA Team. “Univla: learning to act anywhere with task-centric latent actions.” 2025.
[8] LoTA-QAF Team. “LoTA-qaf: lossless ternary adaptation for quantization-aware fine-tuning.” arXiv preprint, 2025.
[13] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. “QLoRA: efficient finetuning of quantized llms.” NeurIPS 36, 2024.
[14] Meta AI. “The llama 3 herd of models.” arXiv preprint arXiv:2407.21783, 2024.
[15] Apple AI/ML. “Apple intelligence foundation language models.” arXiv preprint arXiv:2407.21075, 2024.
[17] Guo, et al. “Towards floating point-based attention-free llm: hybrid pim with non-uniform data format and reduced multiplications.” 2024.
[19] He, K., et al. “Deep residual learning for image recognition.” CVPR, 2016.
[20] Hendrycks, D., & Gimpel, K. “Gaussian error linear units (gelus).” arXiv preprint arXiv:1606.08415, 2016.
[22] Hu, E. J., et al. “Lora: low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685, 2021.
[24] BitNet Team. “The era of 1-bit llms: all large language models are in 1.58 bits.” 2024.
[25] PIM Team. “An overview of processing-in-memory circuits for artificial intelligence and machine learning.” 2023.
[28] Li, J., et al. “Large language model inference acceleration: a comprehensive hardware perspective.” arXiv preprint arXiv:2410.04466, 2024.
[30] Cerebras Team. “Cerebras architecture deep dive: first look inside the hw/sw co-design for deep learning.” 2019.
[33] ParetoQ Team. “Paretoq: scaling laws in extremely low-bit llm quantization.” 2024.
[34] llama.cpp Team. “Llamacpp.” GitHub, 2023.
[36] BitNet Team. “BitNet b1.58 2b4t technical report.” 2024.
[37] Falcon Team. “The era of 1-bit llms.” 2024.
[40] Edge AI Team. “Mobile edge intelligence for large language models: a contemporary survey.” 2024.
[42] Tesla. “Dojo: the microarchitecture of tesla’s exa-scale computer.” 2023.
[43] Taub, D. “A short review of read-only memories.” IEE Proceedings, 1963.
[44] Vaswani, A., et al. “Attention is all you need.” NeurIPS, 2017.
[47] Ladder Team. “Ladder: enabling efficient low-precision deep learning computing through hardware-aware tensor transformation.” 2024.
[48] Tina Team. “Tina: tiny reasoning models via lora.” 2025.
[49] Wang, W., et al. “ROMA: a read-only-memory-based accelerator for qlora-based on-device llm.” arXiv preprint arXiv:2503.12988, 2025.
[50] T-MAC Team. “T-mac: cpu renaissance via table lookup for low-bit llm deployment on edge.” 2024.
[54] 3D Memory Team. “Enabling on-device large language models with 3d-stacked memory.” 2024.
[59] Efficient LLM Team. “A survey on efficient inference for large language models.” 2024.
本文基于 arXiv:2602.20662 论文自动生成,采用 paper_to_blog 工作流转换。