Research Article
Orion: 苹果神经引擎 (ANE) 上的 LLM 训练与推理系统
Orion: Characterizing and Programming Apple’s Neural Engine for LLM Training and Inference
原文链接: arXiv:2603.06728 GitHub
摘要
超过 20 亿台 Apple 设备配备了神经处理单元 (NPU)——Apple Neural Engine (ANE),但这个加速器几乎从未被用于大型语言模型工作负载。CoreML(Apple 公开的 ML 框架)强加了不透明的抽象,阻止了直接的 ANE 编程,且不支持设备端训练。
本文介绍了 Orion,据我们所知,这是第一个开放的端到端系统,结合了直接 ANE 执行、编译器流水线和使用检查点恢复的稳定多步训练,通过 Apple 的私有 ANEClient 和 ANECompiler API 完全绕过 CoreML。
在 M4 Max 上,Orion 实现了 GPT-2 124M 推理 170+ tokens/s,并在 22 分钟内完成了 TinyStories 上 110M 参数 transformer 的 1000 步稳定训练,零 NaN 发生。
1. 问题定义
Apple 的 Neural Engine (ANE) 是自 A11 Bionic (2017) 以来每个 Apple 硅芯片中都存在的专用神经处理单元。M4 世代的 ANE 在 16 个核心上提供高达 38 TOPS (INT8) 的性能,在原始吞吐量上与离散 AI 加速器相媲美。超过 20 亿台活跃的 Apple 设备携带某种变体的此硬件。
然而,尽管有如此庞大的安装基础,ANE 仍然是大型语言模型的”黑暗加速器”:
- 没有公开框架支持 ANE 上的 LLM 训练
- 推理框架普遍通过 Metal targeting GPU 或 CPU
- CoreML 作为黑盒调度器,开发者无法强制 ANE 执行
- ANE 的原生指令集(从 MIL 编译)未公开文档
- 编译和评估 API 位于私有框架中
核心问题是 Apple 的软件栈。CoreML 是唯一公开的 ANE 接口,但它作为一个黑盒调度器运行,在运行时决定是否将操作分派给 CPU、GPU 或 ANE。开发者无法强制 ANE 执行、检查 ANE 程序或执行梯度计算。
2. 方法框架
Orion 的结构分为五层,如图 1 所示:
 图 1: Orion 架构栈。每层仅与其直接邻居通信。编译器和运行时共同从模型层抽象出 ANE 约束。
图 1: Orion 架构栈。每层仅与其直接邻居通信。编译器和运行时共同从模型层抽象出 ANE 约束。
2.1 编译器流水线
Orion 编译器将高级图 IR 转换为可 ANE 执行的 MIL 程序。图 IR 支持 27 种操作,维护所有边的显式张量形状信息。
优化流水线以定点循环运行 5 个pass(最多 20 次迭代):
- 死代码消除 (DCE):通过反向行走标记从输出可达的节点;移除不可达节点
- 恒等消除:移除无操作转换(相同类型)、重塑(相同形状)和恒等转置
- 转换融合:消除往返转换(如 fp16→fp32→fp16)
- SRAM 注释:根据 32 MB 片上 SRAM 预算估算工作集大小;超出时发出警告
- ANE 约束验证:检查禁止的操作(concat)、最小张量大小、权重要求和输出变量活性
2.2 运行时
运行时管理 ANE 程序的生命周期:编译、缓存、评估和 I/O。关键设计决策包括:
- 程序缓存:编译后的程序使用复合键缓存(模型名称、层索引、序列长度、权重版本)
- IOSurface I/O:所有张量数据驻留在 IOSurface 支持的内存中,实现 CPU 和 ANE 之间的零拷贝共享
- 增量编译:使用手术式重载方法,绕过 ANECCompile() 完全消除~119 编译限制
3. ANE 约束特征化
本文的核心贡献之一是 consolidating 20 个 ANE 编程约束的目录,其中 14 个是在 Orion 开发期间新发现的:
| # | 约束 | 症状 | 解决方案 | 来源 |
|---|---|---|---|---|
| 1 | concat MIL 操作被 ANE 编译器拒绝 | 编译失败 | 拆分为独立程序 | O |
| 2 | 多输出缓冲区必须具有统一大小 | 评估时 0x1d 错误 | 填充输出到最大大小 | O |
| 3 | 多输出表面按字母顺序排序 | 静默错误数据 | 按排序顺序命名输出 | O |
| 4 | 最小~49 KB IOSurface 用于评估 | 评估时 0x1d 错误 | 填充 seq 维度≥16 | O |
| 5 | 每进程~119 次编译限制 | 静默失败/崩溃 | exec() 重启 | P |
| 6 | SDPA 因果掩码被静默忽略 | 注意力错误 | 手动因果掩码 | P* |
| 7 | 权重在编译时烘焙 | 过时权重 | 更新后重新编译 | P |
| 8 | BLOBFILE 偏移是 uint64(64),不是 128 | 垃圾权重 | 修正 MIL 中的偏移 | O |
| 9 | MIL 文本必须是 NSData,不是 NSString | 立即崩溃 | 编码为 UTF-8 数据 | O |
| 10 | gelu 不是有效的 MIL 激活 | 编译失败 | Tanh 近似 | O |
| 11 | 权重量典必须是@{},不是 nil | 立即崩溃 | 传递空字典 | O |
| 12 | matmul 转置标志需要命名常量 | MIL 拒绝 | 发射常量节点 | O |
| 13 | conv 不支持 bias=参数 | MIL 拒绝 | 独立 add 操作 | O |
| 14 | 输出变量必须引用活动(优化后)节点 | 无效程序 | DCE 后更新引用 | O |
| 15 | exec() 重启开销~50 ms | 延迟成本 | 每进程批处理步骤 | P |
| 16 | 32K 通道卷积被拒绝 | 编译失败 | CPU 回退或分块 | O |
| 17 | Conv 1×1 比 matmul 快 3× | 性能差距 | 优先 conv 公式 | P |
| 18 | 多输入表面必须具有统一分配大小 | 评估时 0x1d 错误 | 按最大大小分配所有输入 | O |
| 19 | 多输入表面按字母顺序排序 | 静默错误数据 | 按排序顺序命名输入 | O |
| 20 | ANE 将平面缓冲区读取为打包 [1,C,1,S] | 静默错误数据 | 在缓冲区开始写入打包数据 | O |
表 3: ANE 约束目录。来源:P = prior work, O = Orion 开发期间发现,= maderix/ANEgpt 代码库确认*
4. 核心创新:增量编译 (Delta Compilation)
4.1 问题
ANE 的”编译 - 然后 - 分派”模型与梯度下降存在根本性矛盾:每次权重更新都需要将新权重烘焙到编译后的程序中。在 Orion v1.0 中,这意味着每个训练步骤需要完全重新编译 60 个带权重的内核(~4,200 ms),占用 83.9% 的墙时间。
4.2 解决方案
Orion v2.0 引入了增量编译技术,通过利用 ANEModel 对象的 unload/reload 接口来更新权重,而无需调用编译器:
v1.0: 完全重新编译
Adam 更新 → 保存 BLOBFILE → 解析 MIL → ANECCompile() → 加载模型 → ANE 评估
~70 ms/内核
v2.0: 增量重载
Adam 更新 → 保存 BLOBFILE → 卸载模型 → 写入文件 → 重载模型 → ANE 评估
~9 ms/内核
4.3 性能提升
| 指标 | v1.0 | v2.0 | 提升 |
|---|---|---|---|
| 训练时间(计算) | 908 ms | 849 ms | ~1× |
| 重新编译/重载时间 | 4,200 ms | 494 ms | 8.5× |
| 总步骤时间 | 5,108 ms | 1,345 ms | 3.8× |
| 重新编译占步骤% | 83.9% | 36.8% | -47.1 pp |
| 1000 步墙时间 | ~85 min | 22.4 min | 3.8× |
| 进程模型 | 1 步/进程 | 单进程 | — |
| 训练期间编译 | 72/步 | 0 | 消除 |
表 6: 训练步骤时间分解:v1.0(完全重新编译)vs v2.0(增量重载)
 图 3: 训练步骤时间分解。v1.0 将 83.9% 的每个步骤用于完全 ANE 重新编译。v2.0 的增量重载通过完全绕过 ANECCompile() 将其减少到 494 ms,产生 3.8× 总加速。
图 3: 训练步骤时间分解。v1.0 将 83.9% 的每个步骤用于完全 ANE 重新编译。v2.0 的增量重载通过完全绕过 ANECCompile() 将其减少到 494 ms,产生 3.8× 总加速。
5. LoRA Adapter-as-Input
由于 ANE 在编译时烘焙权重,传统上将模型适应新任务需要完全重新编译。Orion 实现了 LoRA,关键架构决策是:适配器矩阵 A 和 B 作为 IOSurface 输入传递,而不是烘焙权重。这使得无需任何重新编译即可热交换适配器。
对于线性层 Y = XWbase,LoRA 融合计算为:
Y = XWbase + α · (XA)B
其中 Wbase ∈ R^(d×d) 作为 BLOBFILE 权重烘焙,A ∈ R^(d×r), B ∈ R^(r×d)(秩 r « d)是 IOSurface 输入。
 图 4: LoRA 融合线性层。基础权重 Wbase 烘焙到编译的 ANE 程序中(蓝色)。适配器矩阵 A、B 作为 IOSurface 输入传递(绿色),可以无需重新编译即可交换。
图 4: LoRA 融合线性层。基础权重 Wbase 烘焙到编译的 ANE 程序中(蓝色)。适配器矩阵 A、B 作为 IOSurface 输入传递(绿色),可以无需重新编译即可交换。
6. 数值稳定性
在 ANE 上实现稳定训练需要解决三个相互作用的 bug,这些 bug 导致上游 ANEgpt 系统在第一个训练步骤后 100% NaN 发散。
6.1 Bug 1: 恢复时的过时程序
根本原因:ANE 程序在检查点权重加载之前编译。前向传递使用过时(预检查点)权重,而后向传递期望与新权重一致的梯度。
修复:延迟编译。程序现在在检查点加载后编译,确保烘焙到每个程序中的权重与当前优化器状态匹配。
6.2 Bug 2: fp16 溢出级联
根本原因:ANE 原生在 fp16(±65,504 动态范围)中运行。大的中间激活溢出到±∞,通过 softmax 和交叉熵传播产生 NaN 损失值。
修复:激活钳制。在 softmax 和层归一化之前,激活被钳制到 [-65504, +65504]。
6.3 Bug 3: 损坏的 BLOBFILE 权重
根本原因:当检查点张量布局与预期的 MIL 权重量典格式不匹配时,BLOBFILE 写入器产生损坏的权重数据。
修复:梯度净化。在写入 BLOBFILE 之前,所有梯度值被净化:NaN→0, ±∞→±65504。
6.4 稳定性验证
| 指标 | 值 |
|---|---|
| 测试的恢复链 | 5 |
| 每链步骤 | 5(每个在新进程中) |
| 总训练步骤 | 25 |
| NaN / Inf 发生 | 0 / 25 |
| 损失单调递减 | 5 / 5 链 |
| 步骤 1 损失(均值±标准差) | 13.975 ± 0.003 |
| 步骤 5 损失(均值±标准差) | 13.913 ± 0.007 |
| 步骤时间(均值±标准差) | 913 ± 30 ms |
| 吞吐量(均值) | 0.612 TFLOPS |
| exec() 重启成功率 | 25 / 25 |
表 7: 训练稳定性压力测试结果(Stories110M, lr=10^-5, grad accum=4, M4 Max)
 图 5: 三 bug NaN 修复前后的训练损失。ANEgpt 在步骤 2 以 100% 可重复性发散到 NaN(红色)。Orion 在 5 步检查点恢复中实现稳定、单调递减的损失(绿色)。
图 5: 三 bug NaN 修复前后的训练损失。ANEgpt 在步骤 2 以 100% 可重复性发散到 NaN(红色)。Orion 在 5 步检查点恢复中实现稳定、单调递减的损失(绿色)。
7. 实验结果
7.1 推理性能
| 配置 | 吞吐量 | 延迟 (p50) |
|---|---|---|
| CPU 解码 | 283 tok/s | 3.48 ms/tok |
| ANE 全向前(解码) | 170 tok/s | 5.76 ms/tok |
| ANE 预填充(首次调用) | 12 tok/s | — |
| ANE 预填充(缓存) | 165 tok/s | — |
表 9: GPT-2 124M 推理性能(M4 Max)
 图 6: M4 Max 上 GPT-2 124M 推理吞吐量。首次调用 ANE 预填充包括~1015 ms 编译时间。CPU 解码更快,因为每个分派的 ANE 的~2.3 ms IOSurface 往返开销。
图 6: M4 Max 上 GPT-2 124M 推理吞吐量。首次调用 ANE 预填充包括~1015 ms 编译时间。CPU 解码更快,因为每个分派的 ANE 的~2.3 ms IOSurface 往返开销。
7.2 训练性能
| 指标 | v1.0 | v2.0 |
|---|---|---|
| 计算时间(均值) | 908 ms/步 | 849 ms/步 |
| 重新编译/重载时间 | 4,200 ms/步 | 494 ms/步 |
| 总步骤时间 | 5,108 ms/步 | 1,345 ms/步 |
| 吞吐量 | 0.612 TFLOPS | 0.656 TFLOPS |
| 1000 步墙时间 | ~85 min | 22.4 min |
| NaN 发生 | 0 / 1,000 | 0 / 1,000 |
| 进程模型 | 1 步/进程 | 单进程 |
表 10: Stories110M 训练性能(M4 Max)
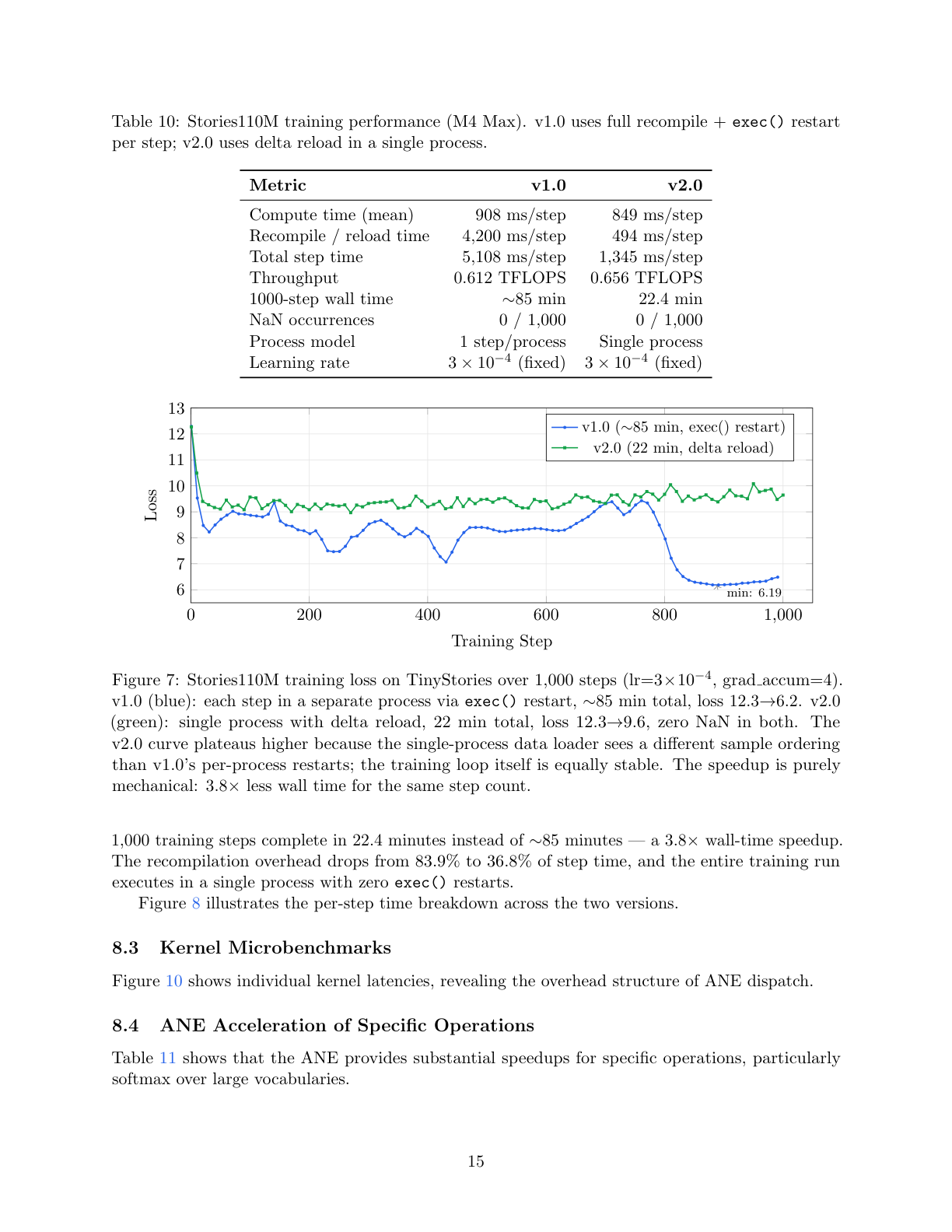 图 9: 1000 步训练墙时间对比。v2.0(增量重载)在 22 分钟内完成,而 v1.0(完全重新编译)需要~85 分钟,加速 3.8×。
图 9: 1000 步训练墙时间对比。v2.0(增量重载)在 22 分钟内完成,而 v1.0(完全重新编译)需要~85 分钟,加速 3.8×。
7.3 框架对比
| 框架 | 硬件 | 训练 | ANE 直接 | 编译器 |
|---|---|---|---|---|
| MLX | GPU | 是 | 否 | 是 |
| llama.cpp | CPU+GPU | 否 | 否 | 否 |
| MLC-LLM | GPU | 否 | 否 | 是 |
| CoreML | CPU/GPU/ANE | 否 | 否 | 是 |
| Orion | ANE | 是 | 是 | 是 |
表 12: Apple 硅上的 LLM 框架。Orion 独特地直接 targeting ANE 用于训练和推理,具有增量编译用于权重更新和 LoRA 热交换。
8. 优点与局限
优点
- 首个开放系统:据我们所知,第一个结合直接 ANE 执行、编译器流水线和稳定多步训练的开放端到端系统
- 3.8× 训练加速:通过增量编译将 1000 步训练时间从 85 分钟减少到 22 分钟
- 8.5× 重新编译加速:从 4,200 ms 减少到 494 ms 每步
- 20 个约束目录:consolidating 20 个 ANE 编程约束,其中 14 个是新发现的
- LoRA 热交换:无需重新编译即可交换低秩适配器
- 数值稳定:解决三个 NaN 诱导 bug,实现零 NaN 训练
- 开源发布:MIT 许可,完整的 Objective-C 运行时
局限
- 使用私有 API:可能在未通知的情况下更改
- 增量编译仍占 36.8%:进一步优化(内存中权重修补)可能
- 仅在 M4 Max 上验证:其他 Apple 硅变体可能有不同的 ANE 配置
- 未评估下游任务:训练展示稳定优化但未在下游任务上评估
- 不支持量化:INT8/INT4 尚未支持
- 无学习率调度:未实现 warmup/decay
- LoRA 推理未完全集成:尚未连接到完整的 Stories110M 推理流水线
9. 讨论
NPU vs GPU 权衡
在 M4 Max 上,GPU(通过 MLX 或 Metal)目前为 LLM 推理实现比 ANE 更高的绝对吞吐量。CPU 基线(283 tok/s)也因每分派 IOSurface 开销而优于 ANE 解码(170 tok/s)。
然而,ANE 有三个优势:
- 零空闲功耗:ANE 在未使用时硬电源门控,非常适合始终在线推理
- 专用硅:ANE 推理使 GPU 和 CPU 完全自由用于其他工作负载
- 特定操作加速:大词汇表上的 softmax 在 ANE 上比 CPU 快 33.8×
对其他 NPU 的启示
我们记录的许多约束(表 3)可能是 ANE 微架构和编译器的产物,而非基本 NPU 限制。然而,未文档化限制、静默失败和编译时权重烘焙的模式可能适用于其他供应商 NPU(Qualcomm Hexagon、Samsung NPU、Google TPU Edge)。
10. 总结
我们介绍了 Orion,据我们所知,第一个用于直接编程 Apple Neural Engine 以进行 LLM 推理和稳定、可恢复训练的开放端到端系统。
基于 maderix 的奠基性硬件特征化工作,我们将 ANE 约束的公共知识扩展到 consolidating 20 个限制的目录,包括 14 个新发现的 MIL IR、内存和 I/O 约束。
关键发现:ANE 的编译时权重烘焙(以前被认为是训练的基本瓶颈)可以通过增量编译绕过:卸载编译后的程序、修补磁盘上的权重文件、重新加载。这将每步重新编译从 4,200 ms 减少到 494 ms(8.5×),实现 22 分钟内 1000 步训练,零 NaN 发生。
ANE 代表了用于设备端 AI 的巨大、未开发的资源:数十亿设备携带专用神经处理硬件,但没有公开框架充分利用它。通过开源 Orion,我们旨在使研究社区能够基于此特征化进行构建,开发下一代 NPU 原生 AI 系统。
参考文献
- Ramchand Kumaresan. Orion: Characterizing and Programming Apple’s Neural Engine for LLM Training and Inference. arXiv preprint arXiv:2603.06728, 2026.
- maderix. Apple Neural Engine reverse-engineering and characterization. https://github.com/mechramc/maderix, 2026.
- ANE Research Community. ANEgpt: Training language models on apple neural engine. https://github.com/anegpt/anegpt, 2026.
- Hollemans. Neural engine characteristics through CoreML experiments. https://github.com/hollance/neural-engine, 2022.
- Apple Inc. Core ML: Integrate machine learning models into your app. https://developer.apple.com/documentation/coreml, 2023.
开源: Orion 在 https://github.com/mechramc/Orion 以 MIT 许可发布。仓库包括所有运行时源代码(Objective-C)、用于从 HuggingFace 格式一次性权重转换的 Python 脚本、基准测试工具和文档。