Research Article
Speculating Experts Accelerates Inference for Mixture-of-Experts: 通过专家预取加速 MoE 推理
Speculating Experts Accelerates Inference for Mixture-of-Experts: 通过专家预取加速 MoE 推理
原文链接: arXiv:2603.19289 代码
摘要
本文提出了一种专家预取方案(expert prefetching scheme),通过利用当前计算的内部模型表示来预测未来专家,使得 CPU-GPU 内存传输能够与计算重叠。在多个 MoE 架构上的实验表明,该方法可以实现5-14% 的每输出令牌时间(TPOT)降低,同时在大多数情况下保持下游任务准确性。
技术总结
问题定义
Mixture-of-Experts (MoE) 模型通过稀疏激活在保持每令牌计算量减少的同时扩展了大语言模型的容量。然而,在内存受限的推理设置中,专家权重必须卸载到 CPU,导致解码过程中 CPU-GPU 传输成为性能瓶颈。
“In memory-constrained inference settings, expert weights must be offloaded to CPU, creating a performance bottleneck from CPU-GPU transfers during decoding.”
以 Qwen3-30B-A3B 在 A6000 GPU 上为例,CPU-GPU 内存传输占每输出令牌时间(TPOT)的84-88%,而计算仅占很小一部分。因此,通过减少这些昂贵的内存传输可以实现显著的推理速度提升。
方法框架
本文提出了一种推理时专家预取方案,利用内部模型表示来预测近期的专家选择。核心思想是使用当前层的归一化残差流和默认向量构建准隐藏状态(quasi-hidden state),用于预测下一层的专家。
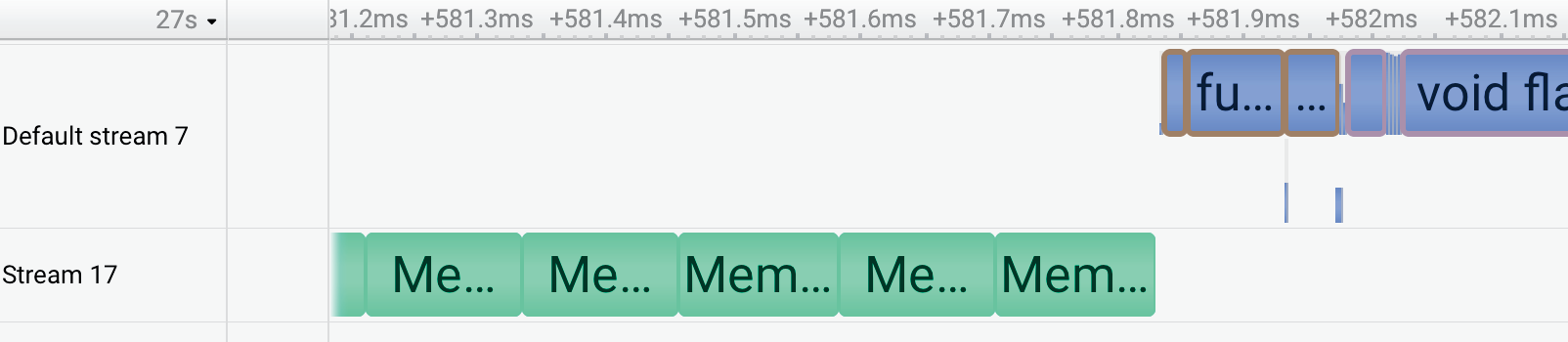 图 1:专家预取在 pre-norm MoE 块中的工作流程。第 l 层的归一化残差流 s_l 和默认向量 d_l 形成准隐藏状态 q_l,用于预测下一层的专家,使 CPU-GPU 内存传输能够与计算重叠。(来源:原文 Figure 1)
图 1:专家预取在 pre-norm MoE 块中的工作流程。第 l 层的归一化残差流 s_l 和默认向量 d_l 形成准隐藏状态 q_l,用于预测下一层的专家,使 CPU-GPU 内存传输能够与计算重叠。(来源:原文 Figure 1)
该方法的关键优势在于:
- 无需额外参数:直接利用现有的内部模型表示
- 适用于预训练模型:无需微调即可应用于现有 MoE 模型
- 即插即用:已集成到开源推理引擎 YALIS 中
核心模块
1. 默认向量(Default Vector)
“The default vector d_{l,e} represents the average activation associated with expert e at layer l.”
默认向量表示与每个专家相关的平均激活,通过离线聚合推理期间观察到的激活计算得到。对于给定的令牌,路由器选择专家子集并分配门控权重,层级别的默认表示定义为所选专家默认向量的加权组合。
2. 准隐藏状态(Quasi-Hidden State)
在 pre-norm MoE 架构中,专家路由是通过对注意力后的归一化残差流计算得到的。准隐藏状态定义为:
“q_l = LN_{l+1}(d_l + r_l)”
其中 r_l 是第 l 层的注意力后残差,d_l 是层级别的默认向量,LN_{l+1} 表示应用于下一层专家路由前的归一化。
3. 轻量级神经估计器(Lightweight Neural Estimator)
对于准隐藏状态预测效果不佳的架构(如 Qwen3-30B-A3B 的早期层),作者训练了一个轻量级神经估计器来直接预测路由决策。
“The estimator learns a mapping from the quasi-hidden state q_l to the router logits at layer l+1.”
该估计器是一个前馈网络,带有学习的位置嵌入以考虑层特定的路由行为。通过蒸馏训练,最小化估计器预测的 logits 与真实路由器产生的 logits 之间的 KL 散度。
实验设置
模型配置:
| 模型 | 层数 (L) | 专家数 (E) | 隐藏维度 (H) | 专家隐藏维度 (H_MoE) | 专家内存 | 其他参数内存 |
|---|---|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 128 | 2048 | 768 | ~54 GB | ~3 GB |
| GLM-4.7-Flash | 47 | 64 | 2048 | 1536 | ~53 GB | ~3 GB |
| GPT-OSS-120B | 24 | 32 | 2880 | 2880 | ~213 GB | ~4 GB |
| Qwen3-235B-A22B | 94 | 128 | 4096 | 1536 | ~230 GB | ~14 GB |
硬件配置:
| GPU | HBM | CPU DRAM | CPU↔GPU 链路 | 评估模型 |
|---|---|---|---|---|
| A6000 | 48 GB | 128 GB | PCIe 4.0 | Qwen3-30B-A3B, GLM-4.7-Flash |
| A100 | 80 GB | 256 GB | PCIe 4.0 | GPT-OSS-120B |
| GH200 | 96 GB | 480 GB | NVLink C2C | Qwen3-235B-A22B |
评估指标:
- TPOT (Time Per Output Token):生成每个输出令牌的平均时间
- 专家预测命中率 (Hit Rate):预测专家与真实路由器选择专家的重合度
- 下游任务准确性:在多个基准测试上的表现
优点
1. 显著的性能提升
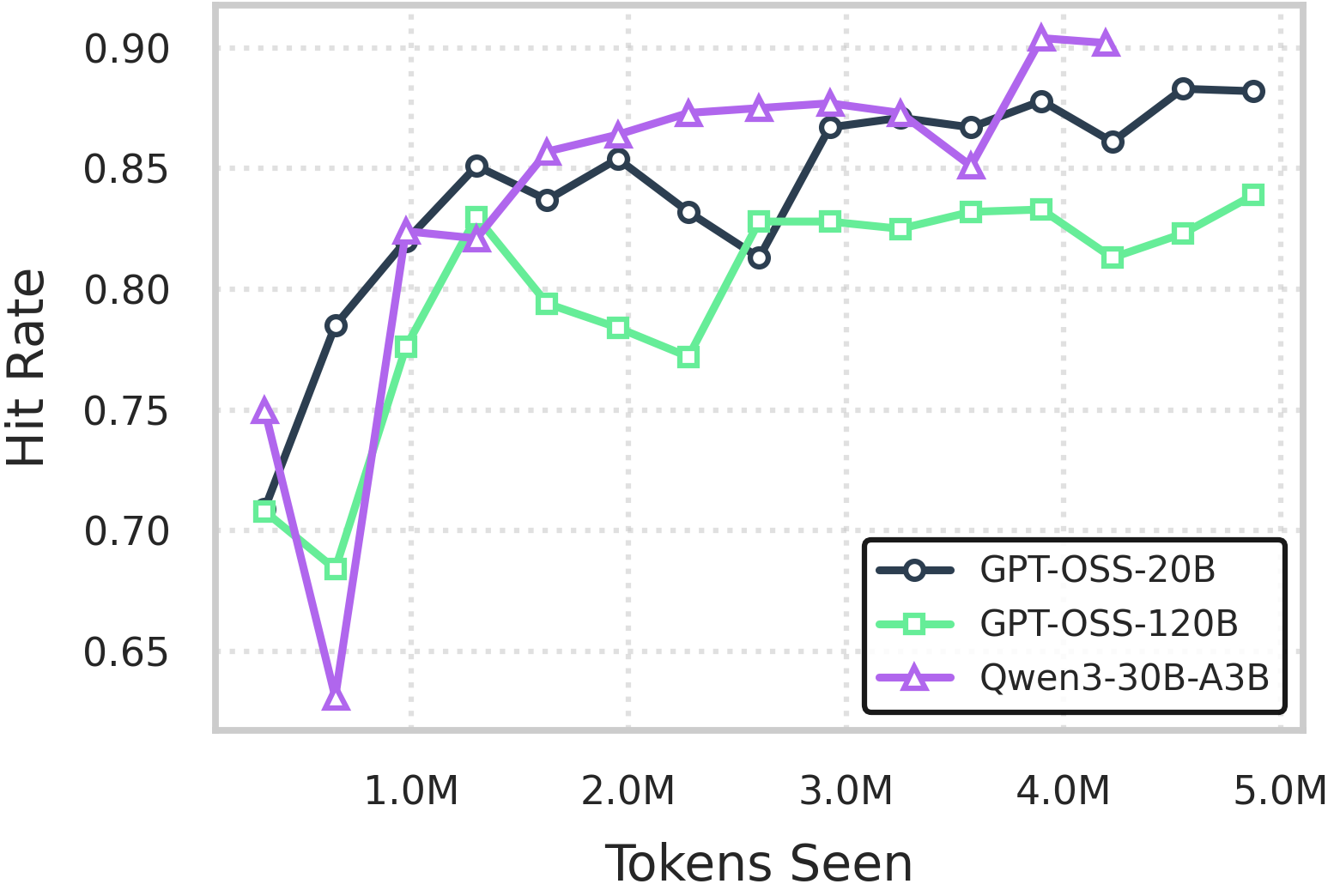 图 8:不同模型的每输出令牌时间(TPOT)对比,比较了按需专家加载和专家预取在不同序列长度下的表现。(来源:原文 Figure 8)
图 8:不同模型的每输出令牌时间(TPOT)对比,比较了按需专家加载和专家预取在不同序列长度下的表现。(来源:原文 Figure 8)
在 Qwen3-30B-A3B 上,预取方案实现了9-14% 的 TPOT 降低,且在更长序列长度下收益更大。在更强大的 GPU(A100 和 GH200)上,最大 TPOT 改进为5-8%,表明预取在较弱 GPU 上提供更大收益。
2. 保持任务准确性
对于 GPT-OSS 系列模型,执行预取专家在大多数任务上保持了与基线相当的性能:
| 方法 | HumanEval | MBPP+ | GSM8k | AIME24 | AIME25 | StrategyQA | 平均 |
|---|---|---|---|---|---|---|---|
| GPT-OSS-120B (基线) | 0.970 | 0.815 | 0.955 | 0.800 | 0.767 | 0.789 | 0.849 |
| GPT-OSS-120B + Router-PF | 0.963 | 0.812 | 0.958 | 0.833 | 0.800 | 0.776 | 0.857 |
| GPT-OSS-120B + Est-PF | 0.951 | 0.804 | 0.949 | 0.700 | 0.700 | 0.760 | 0.811 |
| GPT-OSS-120B + Hybrid-PF | 0.927 | 0.802 | 0.945 | 0.800 | 0.800 | 0.769 | 0.841 |
3. 高效的计算 - 内存重叠
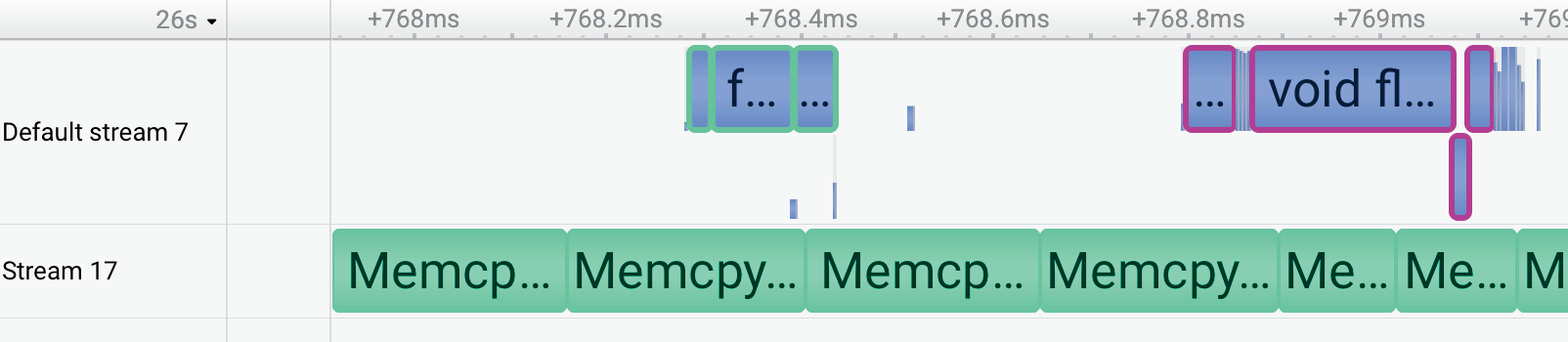 图 2:使用 Qwen-30B-A3B 推理的 Nsight Systems 追踪。与按需加载活动专家(上)相比,专家预取方法(下)有效地将 CPU-GPU 内存传输与 GPU 计算重叠,减少了关键路径上的传输开销。(来源:原文 Figure 2)
图 2:使用 Qwen-30B-A3B 推理的 Nsight Systems 追踪。与按需加载活动专家(上)相比,专家预取方法(下)有效地将 CPU-GPU 内存传输与 GPU 计算重叠,减少了关键路径上的传输开销。(来源:原文 Figure 2)
通过异步预取下一层专家权重,并与当前层 MoE 计算重叠,显著减少了关键路径上的时间。
4. 轻量级估计器的高命中率
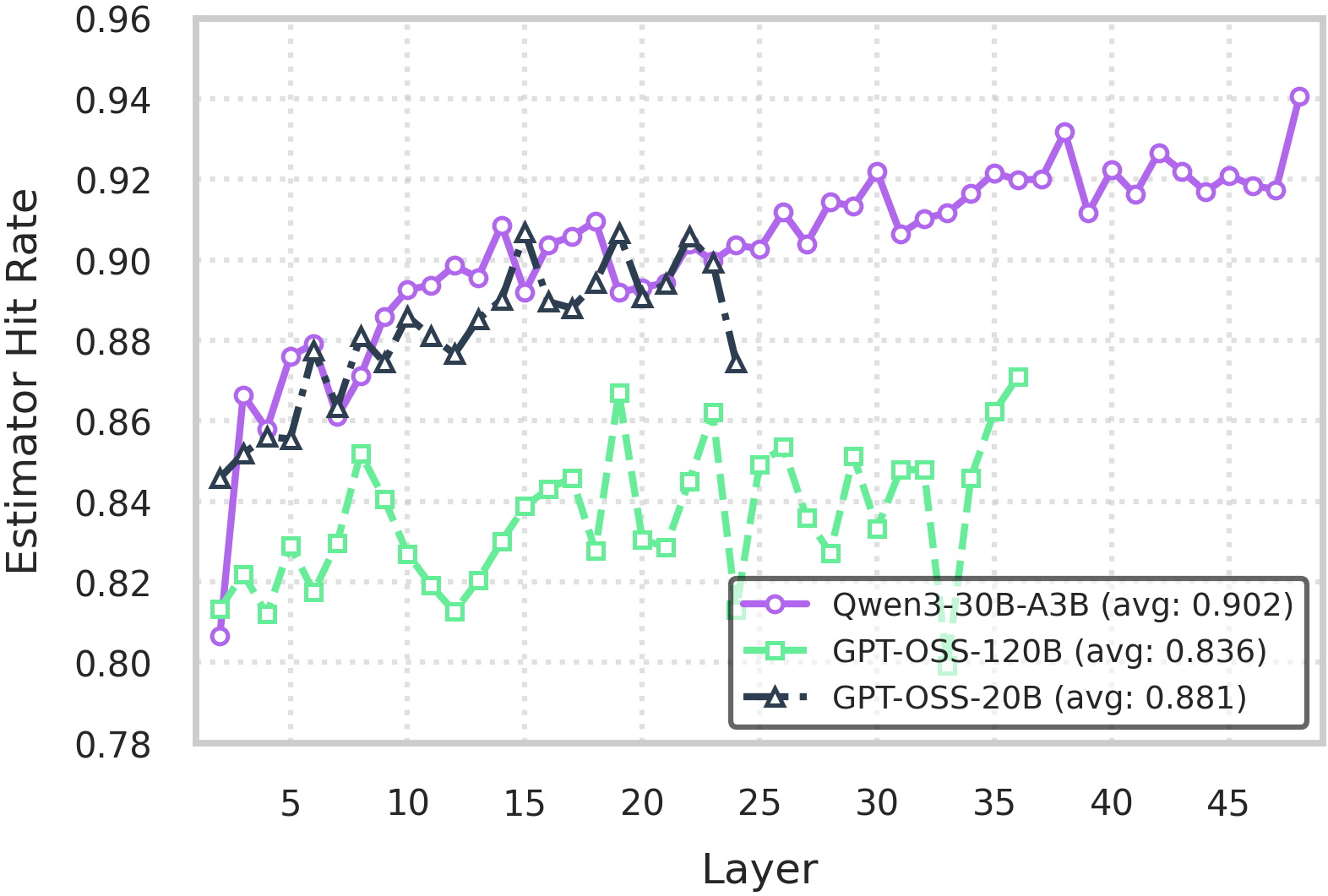 图 9:验证专家命中率与用于训练专家估计器的令牌数量的关系。(来源:原文 Figure 9)
图 9:验证专家命中率与用于训练专家估计器的令牌数量的关系。(来源:原文 Figure 9)
估计器在相对较少的训练令牌下即可达到高预测精度。Qwen3-30B-A3B 的估计器在 4M 令牌后达到约90% 的平均命中率。
局限
1. 架构敏感性
Qwen3-30B-A3B 对基于路由器的推测执行表现出更高的敏感性。特别是在数学密集型任务(如 AIME24 和 GSM8k)上性能下降更明显:
| 方法 | HumanEval | MBPP+ | GSM8k | AIME24 | AIME25 | StrategyQA | 平均 |
|---|---|---|---|---|---|---|---|
| Qwen3-30B-A3B (基线) | 0.939 | 0.762 | 0.950 | 0.800 | 0.733 | 0.719 | 0.817 |
| Qwen3-30B-A3B + Router-PF | 0.860 | 0.659 | 0.576 | 0.467 | 0.600 | 0.683 | 0.641 |
| Qwen3-30B-A3B + Est-PF | 0.915 | 0.741 | 0.918 | 0.667 | 0.567 | 0.691 | 0.750 |
| Qwen3-30B-A3B + Hybrid-PF | 0.909 | 0.762 | 0.946 | 0.700 | 0.600 | 0.681 | 0.766 |
这归因于 Qwen3-30B-A3B 早期层的高表示漂移(representational drift)。
2. 预填充阶段的限制
在预填充阶段,由于提示长度通常足够大,所有专家在每一层都有效激活,任何专家预测或预取策略都简化为加载所有专家。因此,预填充阶段的预取不涉及非平凡的专家选择决策。
3. 硬件依赖性
在更强大的 GPU 上(如 A100 和 GH200),由于更高的计算吞吐量,最大 TPOT 改进限制在 5-8%,相比 A6000 的 12-14% 较低。这表明预取方案的收益受计算 - 复制时间比例的限制。
4. 估计器训练成本
虽然估计器是轻量级的,但仍需要训练:
- Qwen3-30B-A3B:17M 参数,需要 4M 训练令牌
- GPT-OSS-20B:4M 参数,需要 5M 训练令牌
- GPT-OSS-120B:45M 参数,需要 5M 训练令牌
实验结果
专家预测命中率分析
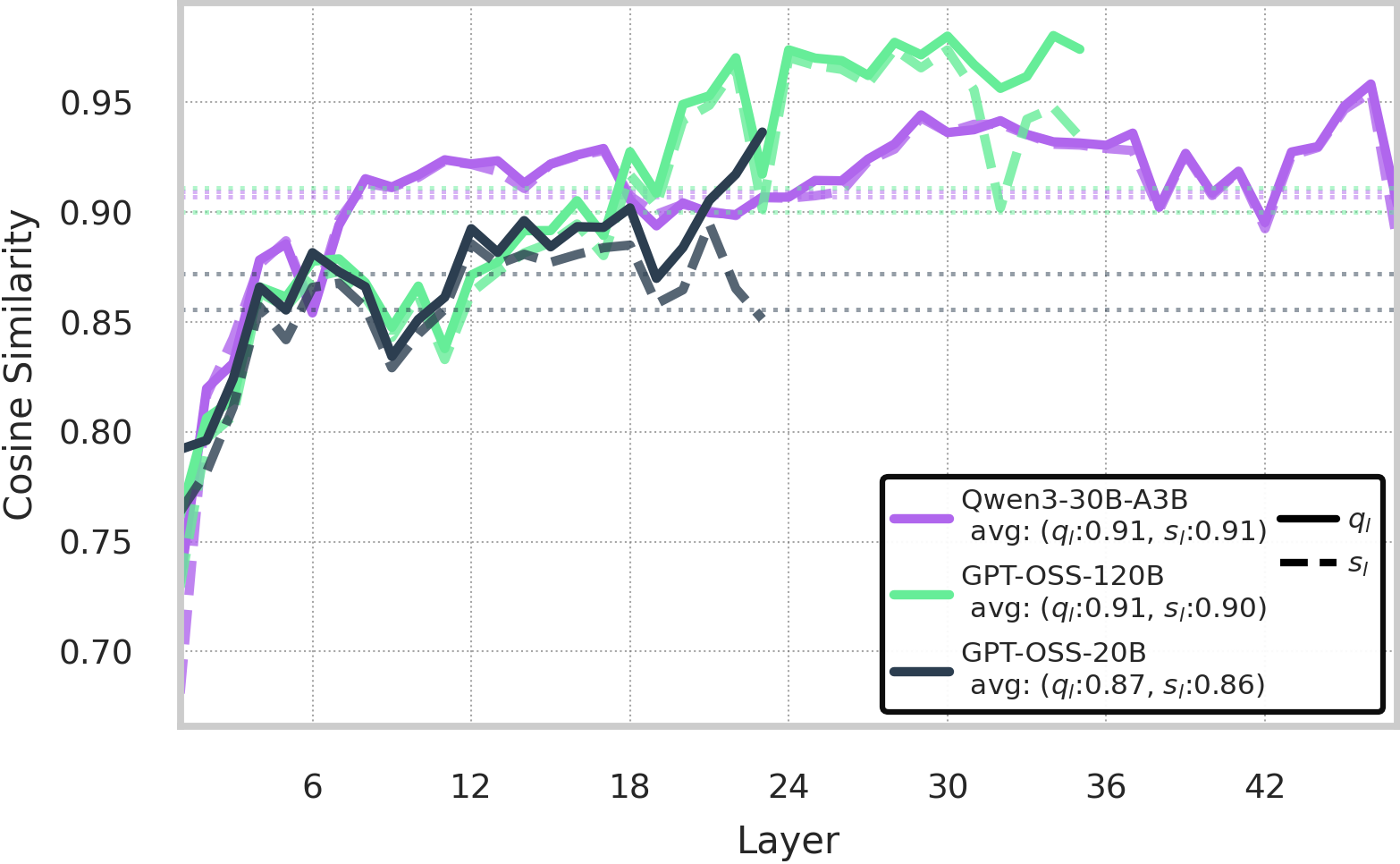 图 3:在层 l 构建的准隐藏状态 q_l 与真实路由器输入 s_{l+1} 之间的余弦相似度对比。(来源:原文 Figure 3)
图 3:在层 l 构建的准隐藏状态 q_l 与真实路由器输入 s_{l+1} 之间的余弦相似度对比。(来源:原文 Figure 3)
在 GPT-OSS 模型上,准隐藏状态显示出比基线 s_l 更高的平均余弦相似度,表明包含默认向量为近似 s_l 和 s_{l+1} 之间的漂移提供了有用的专家条件偏差。
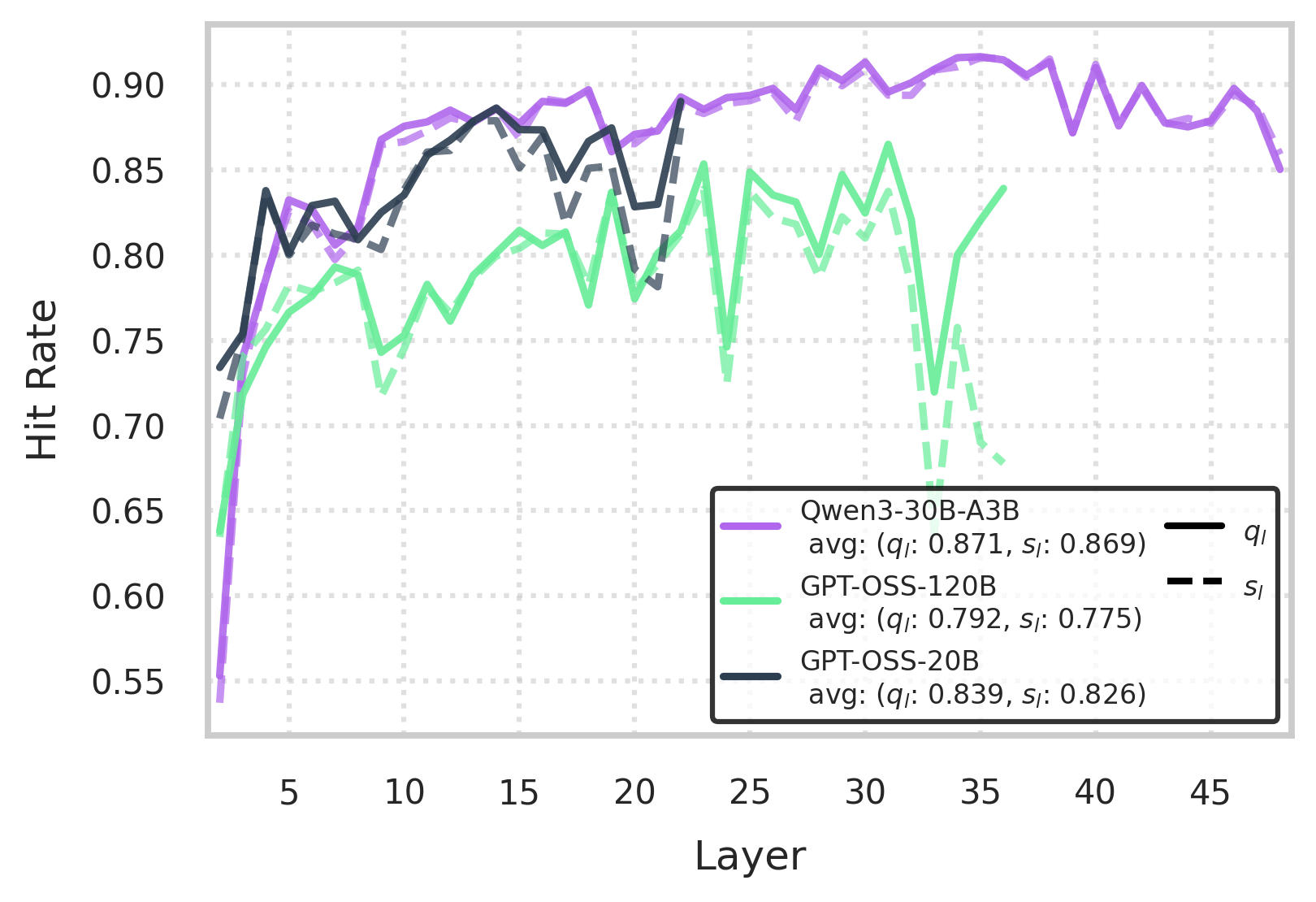 图 4:使用准隐藏状态 q_l 与基线 s_l 获得的各层专家预取命中率(recall@k)。(来源:原文 Figure 4)
图 4:使用准隐藏状态 q_l 与基线 s_l 获得的各层专家预取命中率(recall@k)。(来源:原文 Figure 4)
对于 Qwen3-30B-A3B,大部分层间漂移发生在前两层,导致早期机制的 recall@k 较低。在这些层之后,可忽略的漂移允许平均约90% 的 recall@k。
专家排名对齐分析
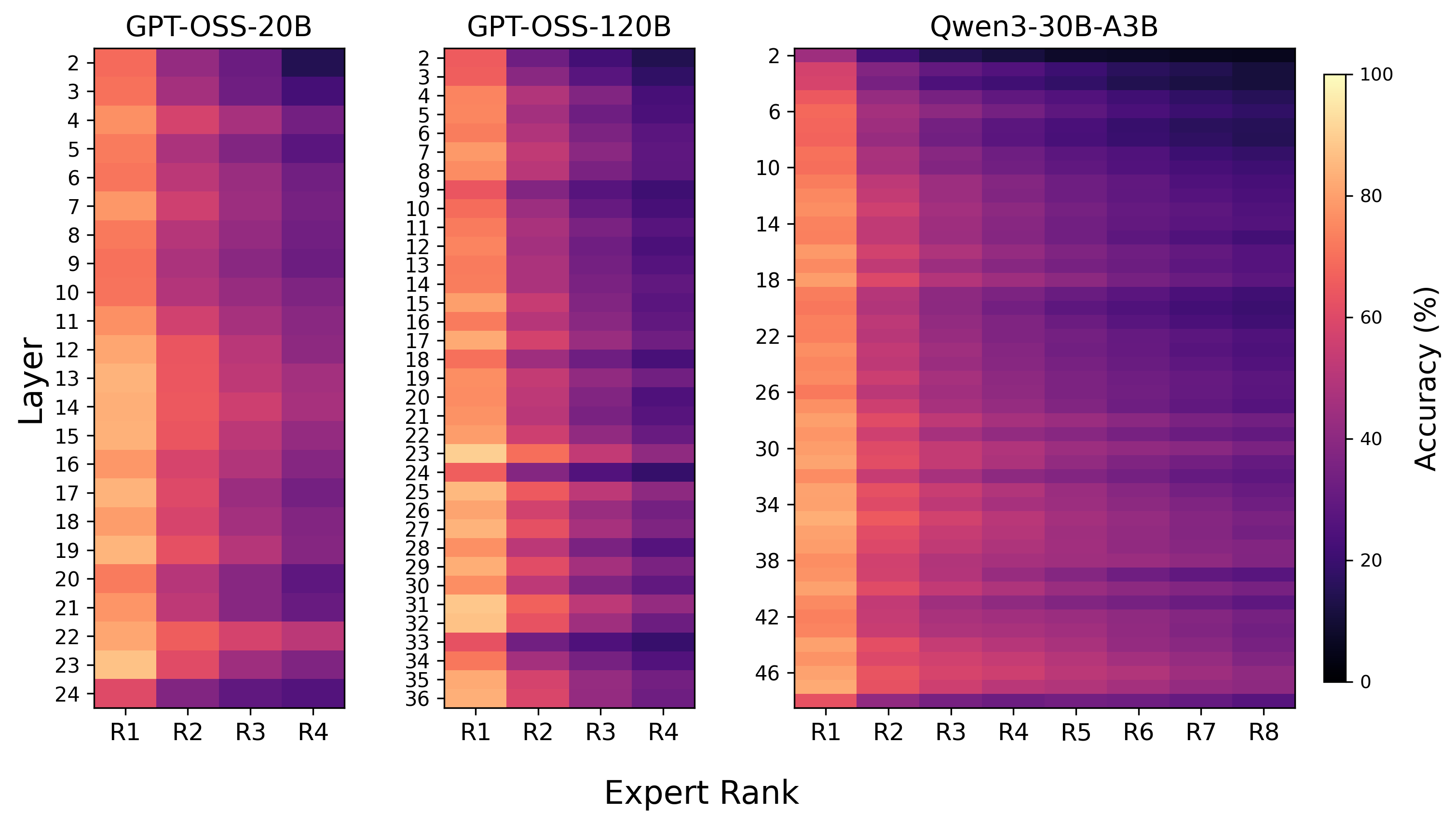 图 5:推测路由与真实路由在各层的专家排名对齐。对于每一层,报告给定排名(由路由权重确定)的专家在预取和真实路由之间匹配的比例。(来源:原文 Figure 5)
图 5:推测路由与真实路由在各层的专家排名对齐。对于每一层,报告给定排名(由路由权重确定)的专家在预取和真实路由之间匹配的比例。(来源:原文 Figure 5)
最高排名的专家(即接收最大路由权重并对 MoE 激活贡献最大的专家)在大多数层中以高命中率被预测。这有助于解释尽管路由预测不完美,下游任务准确性仍保持稳定。
按需加载性能分解
图 7:按需专家加载在不同模型和提示序列长度下的每输出令牌时间分解。(来源:原文 Figure 7)
在 Qwen3-30B-A3B 上,复制时间构成主要瓶颈,占 TPOT 的~84-88%。计算时间仅占总 TPOT 的~8-13%,这形成了可实现改进的上限(根据公式 1)。
预取方案对比
不同预取方案在下游基准测试上的准确性对比见表 1。关键发现:
- GPT-OSS 模型:基于路由器的预取(Router-PF)在大多数任务上保持了与基线相当的性能
- Qwen3-30B-A3B:混合预取(Hybrid-PF)策略恢复了大部分基线性能,同时在低命中率层应用估计器
- 估计器效果:在 GSM8k 上,混合方法恢复了约37% 到 Router-PF 的准确性差距
实现细节
该预取方案已集成到 YALIS(一个轻量级研究推理引擎)中,支持来自 SOTA 框架(如 vLLM)的关键优化,包括:
torch.compile- CUDA Graphs
- 优化的注意力后端
关键实现特性:
- 双缓冲:跨层交替使用 GPU 专家缓冲区,实现计算 - 复制重叠而无需额外同步
- 固定 CPU 内存:卸载的 MoE 权重存储在固定 CPU 内存中,防止操作系统分页,实现比可分页内存更快的 CPU→GPU 传输
- 仅卸载专家权重:非专家参数(注意力和路由器)足够小,可以保留在 GPU 上,避免不必要的传输
- 异步预取:使用独立的 CUDA 流进行异步内存传输,与计算重叠
总结
本文提出了一种推理时专家预取方案,通过利用内部模型表示来预测未来专家选择,使得专家传输能够与计算重叠。主要贡献包括:
- 无参数预取:识别出能够跨现代 MoE 架构预测未来路由决策的内部模型表示
- 保持准确性的推测执行:证明执行预取专家(而非将错误预测视为缓存未命中)通常能保持下游任务准确性
- 优化的推理实现:集成到开源推理引擎中,在资源受限设置下实现5-14% 的 TPOT 降低
- 轻量级神经估计器:对于预取方案不足的架构,引入轻量级估计器显著提高专家预测命中率
通过减少专家卸载带来的成本,这项工作使得大型开源 MoE 模型在消费级硬件上的本地部署更加实用。
参考文献
-
Madan V, Singhania P, Bhatele A, Goldstein T, Panda A. Speculating Experts Accelerates Inference for Mixture-of-Experts. arXiv preprint arXiv:2603.19289, 2026.
-
Panda A, et al. Default Vectors for MoE Routing. 2025.
-
Singhania P, et al. YALIS: A Lightweight Research Inference Engine. 2025.
-
Shazeer N, et al. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ICLR, 2017.
-
Kwon W, et al. vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention. OSDI, 2023.
-
Dao T, et al. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS, 2022.
-
Chen et al. Speculative Expert Offloading for MoE Inference. 2025.
-
Yu et al. Layer-wise Expert Prefetching for MoE Models. 2025a.
-
Zhang et al. Overlapping Communication and Computation in MoE Inference. 2025a.
-
Hwang et al. Pre-Gating for MoE Prefetching. 2024.
本文使用 paper_to_blog 工具自动生成,最后更新:2026-03-26