Research Article
Understanding Bottlenecks for Efficiently Serving LLM Inference With KV Offloading
Understanding Bottlenecks for Efficiently Serving LLM Inference With KV Offloading
原文链接: arXiv:2601.19910
作者: William Meng, Benjamin Lee, Hong Wang
机构: arXiv GenPDF
发布日期: 2025 年 12 月 16 日
技术总结
问题定义
KV 缓存卸载(KV cache offloading)通过将 KV 缓存存储在 CPU DRAM 中来实现长上下文 LLM 推理,但 PCIe 带宽限制造成了严重的瓶颈。随着模型支持越来越长的上下文(从数十万到数百万 token),KV 缓存可能达到数十 GB,迅速耗尽 GPU VRAM 容量。虽然 CPU DRAM 可提供 TB 级容量,但 GPU 通过 HBM 提供 TB/s 级带宽,而 CPU-GPU PCIe 互连仅提供数十 GB/s——相差数个数量级。
“对于缓存 token 数量远多于新 token 的工作负载,这将传统的计算密集型预填充(compute-bound prefill)转变为内存密集型执行(memory-bound execution),导致 GPU 计算资源未被充分利用。”
方法框架
本文开发了一个分析框架,推导出 κ_crit(关键缓存与预填充 token 比率),即执行变为内存受限的临界点。框架核心是两个关键指标:
- κ_ratio = K/T:工作负载中缓存 token 数量(K)与新预填充 token 数量(T)的比率,描述工作负载的内存与计算强度平衡
- κ_crit:硬件的临界比率,计算从计算密集型转变为内存密集型的阈值
当 κ_ratio > κ_crit 时,预填充变为内存受限。κ_crit 由模型因素(κ_M)和硬件因素(κ_HW)共同决定:
κ_crit = κ_M × κ_HW = (F_pfl / B_kv) × (BW_PCIe / C_eff)
其中 F_pfl 是每个预填充 token 的 FLOPs,B_kv 是每个 token 的 KV 缓存字节数,BW_PCIe 是 PCIe 带宽,C_eff 是 GPU 有效计算吞吐量。
核心模块
论文的核心贡献包括三个部分:
-
分析框架:通过 κ_crit 和 κ_ratio 的公式化,将模型与系统架构解耦,使软件优化和硬件优化可以独立推理
-
性能特征分析:在 H100 和 B200 系统上对 ShareGPT、NarrativeQA 和 FinQA 工作负载进行实证测量,发现 PCIe 开销可达预填充计算的 86 倍,占总执行时间的 99%
-
设计启示:识别硬件优化(NVLink C2C、统一 HBM)、模型优化(MLA 注意力机制)和调度策略的改进方向
“典型工作负载的 κ_ratio 值比 κ_crit 超出数个数量级:对话的中位数为 100,文档查询的中位数为 5000,而大多数系统的 κ_crit 小于 15。”
实验设置
硬件平台:
- 8×H100 SXM5 GPU(每个 80GB HBM3,通过 NVLink 4.0 连接)
- AMD EPYC 7R13 CPU(48 核)
- 2 TB DDR4-3200 DRAM
- PCIe 5.0 ×16(峰值双向带宽:128 GB/s)
软件栈:
- vLLM v0.10.1 + LMCache v0.3.5 用于 KV 缓存卸载
- FP16 精度
- 禁用前缀缓存以隔离 PCIe 传输性能
评估模型:
- Llama-3.1-70B(稠密 Transformer,GQA,B_kv = 328 KB/token)
- Qwen3-235B-A22B(稀疏 MoE,GQA,B_kv = 192 KB/token,235B 总参数中激活 22B)
工作负载:
- ShareGPT:90k 对话,685k 轮次
- NarrativeQA:47k 问题,1,572 个叙事文本
- FinQA:7.4k 问题,801 个财务文档
优点
-
理论贡献:首次通过 κ_crit 和 κ_ratio 的形式化分析,揭示了 KV 卸载何时以及为何会导致内存瓶颈,为系统设计提供了清晰的指导原则
-
实证洞察:发现 GPU 在卸载场景下平均仅消耗 28% 的额定 TDP,表明存在严重的资源浪费,这对数据中心的电力基础设施规划有重要影响
-
实用建议:提出了具体的优化方向,包括使用 NVLink C2C(提升κ_crit5.3 倍)、统一 HBM 架构(提升 48 倍)、MLA 注意力机制(减少 2.7-4.7 倍数据需求)和量化技术(INT8 提供 2 倍压缩)
-
调度优化:提出了基于利用率的感知调度策略,通过 VRAM 约束下的 token 预算优化,可以在不增加硬件成本的情况下提高 GPU 利用率
局限
-
MLA 评估不完整:论文尝试评估 DeepSeek-V2 的 MLA 特性,但遇到了实现特定的开销问题,无法准确隔离 PCIe 传输性能,因此将全面的 MLA 评估留待未来工作
-
简化假设:框架使用 2N FLOPs/token 近似 F_pfl,忽略了上下文缩放项 2n_layer·n_ctx·d_attn。对于典型模型这项可以忽略,但对于超大上下文(如 65K token),可能引入约 10% 的误差
-
写入开销未建模:框架专注于从 CPU DRAM 加载 KV 缓存,忽略了将新前缀写回 DRAM 的开销。假设写入操作在预填充之后进行,且双向 PCIe 可以缓解影响,但较大的 T 值可能引入未建模的读写竞争开销
-
量化和压缩未实证验证:虽然论文指出 MLA(2.7-4.7 倍 B_kv 减少)和量化(2-4 倍压缩)可以减少 PCIe 开销,但没有实证表征这些技术,需要未来工作验证预测的收益
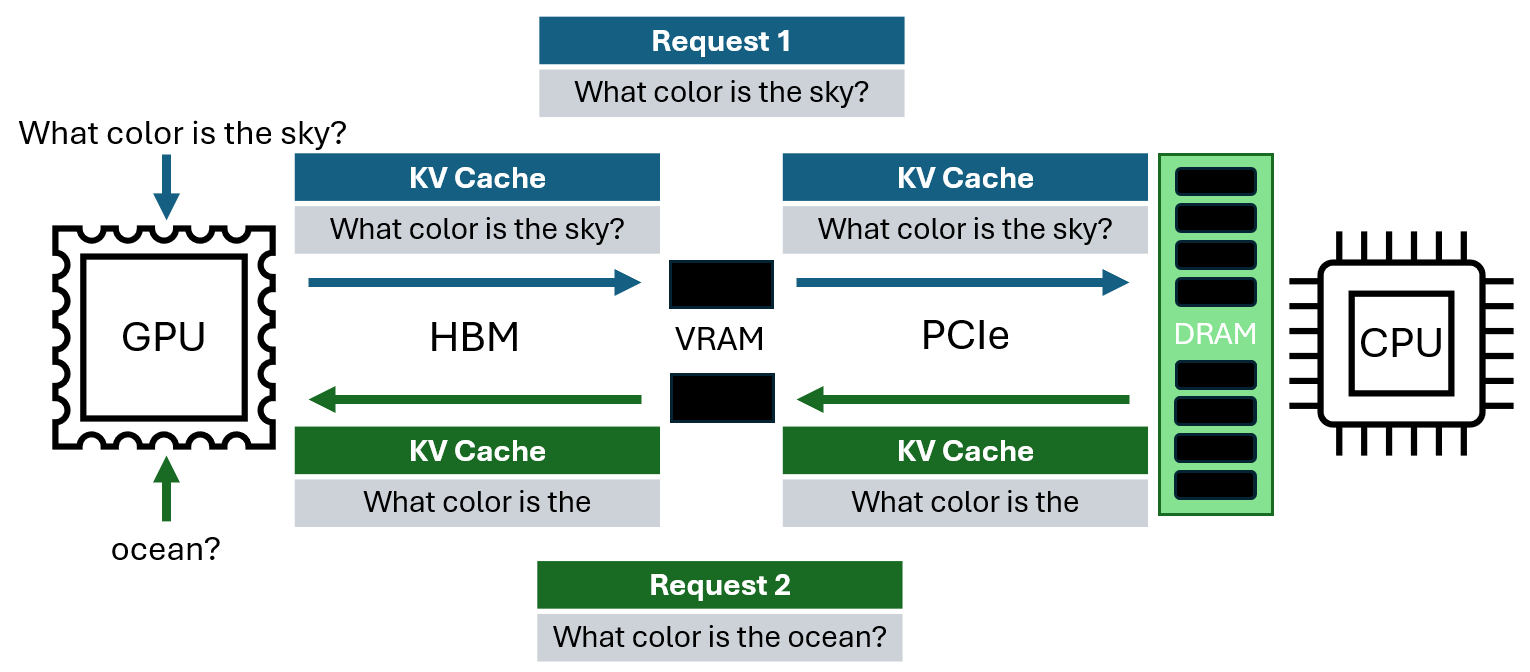 图 1:KV 缓存卸载概述。当服务第二个请求(绿色)时,只有新 token(”ocean”)需要计算;缓存的 token 通过 PCIe 加载。(来源:原文 Figure 1)
图 1:KV 缓存卸载概述。当服务第二个请求(绿色)时,只有新 token(”ocean”)需要计算;缓存的 token 通过 PCIe 加载。(来源:原文 Figure 1)
1. 背景与动机
1.1 LLM 推理的挑战
大型语言模型已成为跨领域的基础设施,从聊天机器人到金融分析和医疗应用。现代 LLM 使用 Transformer 架构,在预填充阶段生成键值(KV)缓存。随着模型支持更长的上下文(数十万到数百万 token),计算成本大幅增加。
在多轮对话或多次查询相同文档时,token 经常重复出现。前缀缓存(Prefix Caching)通过将 KV 缓存存储在 GPU VRAM 中来消除冗余计算。然而,这些缓存可能达到数十 GB,在服务多个并发请求时迅速耗尽 VRAM 容量。
“LLaMA-3.1-405B 为每个 token 生成 500 KB 的 KV 缓存,对于长输入可能达到数十 GB。”
1.2 KV 缓存卸载的权衡
KV 缓存卸载通过将 KV 存储在 CPU DRAM 中来解决 VRAM 约束,其中可提供 TB 级容量。然而,虽然 GPU 提供 TB/s 级的 HBM 带宽,但 CPU-GPU PCIe 互连仅提供数十 GB/s——相差数个数量级。
关键问题:对于缓存 token 数量远多于新 token 的工作负载,这将传统的计算密集型预填充转变为内存密集型执行,导致 GPU 计算资源未被充分利用。
2. 分析框架
2.1 内存受限执行的判定
论文建模了预填充请求的 TTFT(Time To First Token),该请求从 CPU DRAM 加载 K 个缓存 token 并在 GPU 上计算 T 个新预填充 token:
TTFT = t_PCIe + t_prefill = (K · B_kv) / BW_PCIe + (T · F_pfl) / C_eff
其中:
- B_kv:每个 token 的 KV 缓存字节数(取决于层数、注意力头数、头维度和浮点精度)
- F_pfl:每个预填充 token 的 FLOPs(取决于模型架构)
- BW_PCIe:持续的 host-to-device 带宽(GB/s)
- C_eff:有效 GPU FLOPS/s
临界比率:当 PCIe 传输时间主导 GPU 计算时间时,预填充变为内存受限:
κ_ratio = K/T > κ_crit = (F_pfl / B_kv) × (BW_PCIe / C_eff) = κ_M × κ_HW
“κ_crit 是无量纲的。在 roofline 术语中,卸载预填充的计算强度是 AI = (T · F_pfl) / (K · B_kv)。计算与带宽的转换发生在 AI = C_eff / BW_PCIe 处。”
2.2 模型因素(κ_M)
κ_crit 的阈值随计算强度(F_pfl)增加而增加,随 KV 占用(B_kv)减少而减少。使用更高 F_pfl/B_kv 比率的模型(如使用 Multi-Head Latent Attention(MLA)压缩 KV 表示的模型)表现出更高的 κ_crit 值,对内存瓶颈更具弹性。
表 1:不同模型的 κ_M 比较
| 模型 | 激活参数 | 注意力架构 | B_kv (KB/token) | κ_M |
|---|---|---|---|---|
| LLama-3.1-70B | 70B | GQA Dense | 328 | 0.42 |
| LLama-3.1-405B | 405B | GQA Dense | 516 | 1.42 |
| Qwen3-30B-A3B | 3.3B | GQA MoE | 98 | 0.07 |
| Qwen3-235B-A22B | 22B | GQA MoE | 192 | 0.23 |
| Deepseek-V3 | 37B | MLA MoE | 70 | 1.06 |
关键洞察:
- MoE 模型仅激活部分参数,大幅减少了 F_pfl,但 B_kv 不随激活参数缩放。Qwen3-235B-A22B 仅激活 5% 的参数(相比 LLaMA-3.1-405B),但其 B_kv 是 LLaMA-405B 的 37%
- MLA 显著减少了 B_kv。DeepSeek-V3 的 B_kv = 70 KB,仅为 Qwen3-235B-A22B 的 36% 和 LLaMA-405B 的 14%
2.3 硬件因素(κ_HW)
κ_crit 随互连带宽(BW_PCIe)增加而增加,随计算吞吐量(C_eff)减少而减少。维持更高吞吐量的 GPU 更容易受到内存瓶颈的影响,因为更难保持核心有数据供应。
表 2:不同 GPU 和 PCIe 世代的 κ_HW
| GPU | PCIe-4 | PCIe-5 |
|---|---|---|
| B200 | 6.7 | 13.5 |
| H100 | 17 | 34 |
| A100 | 53.8 | 107.5 |
“B200 系统表现出比 H100 高 2.5 倍的 C_eff,而 PCIe 5.0 仅提供比 PCIe 4.0 高 2 倍的带宽。这种不平衡导致 B200 的κ_HW 值 consistently 更低。”
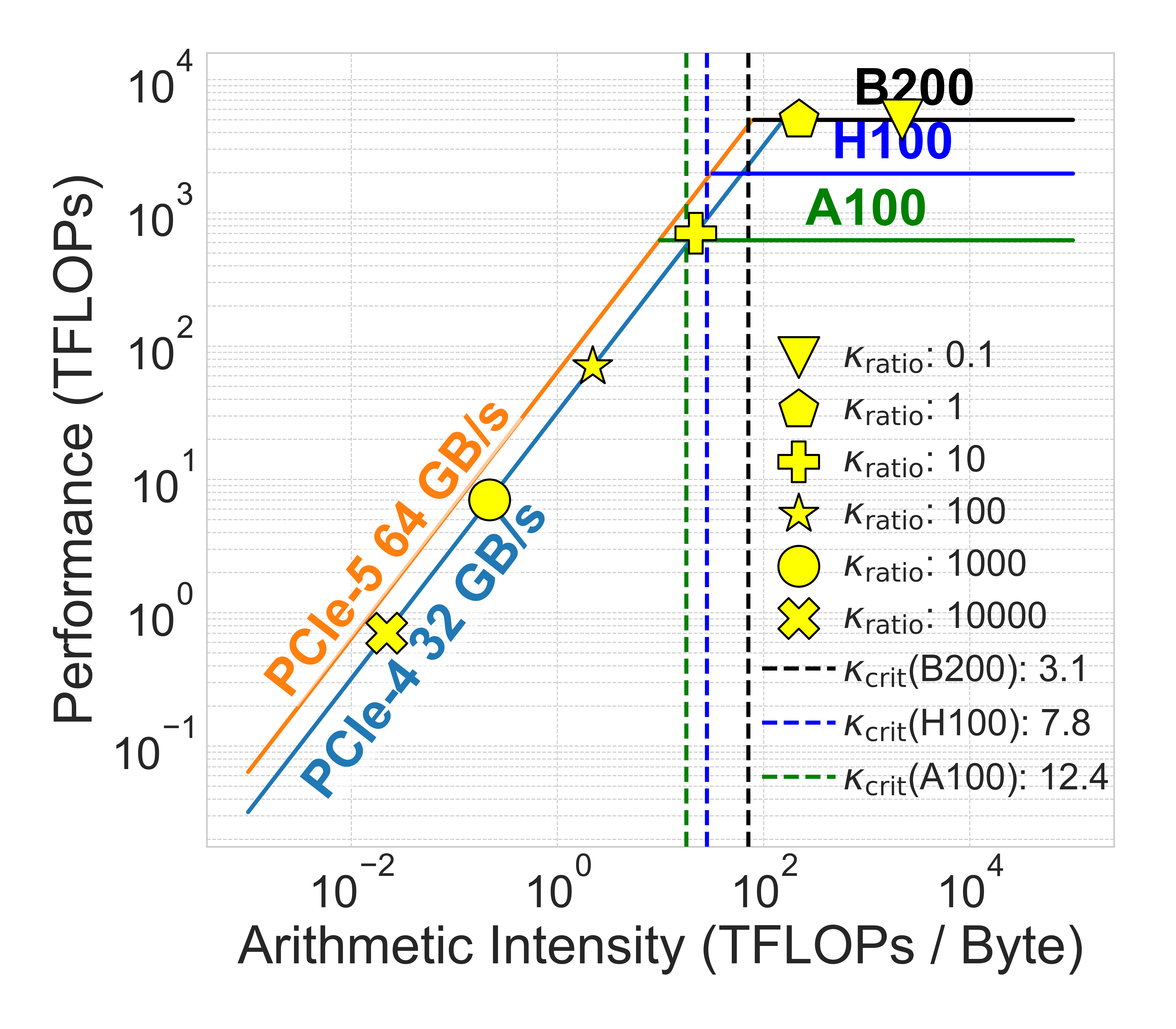 图 4:Roofline 模型分析 Qwen3-235B-A22B(左)和 Deepseek-V3(右)在 NVIDIA B200、H100 和 A100 上的性能。垂直线表示特定硬件的κ_crit。κ_crit 左侧的点为计算受限,右侧为带宽受限。(来源:原文 Figure 4)
图 4:Roofline 模型分析 Qwen3-235B-A22B(左)和 Deepseek-V3(右)在 NVIDIA B200、H100 和 A100 上的性能。垂直线表示特定硬件的κ_crit。κ_crit 左侧的点为计算受限,右侧为带宽受限。(来源:原文 Figure 4)
2.4 案例研究:LLaMA-3.1-405B on H100
对于 LLaMA-3.1-405B 在 PCIe 5.0 的 H100 GPU 上:
- F_pfl = 2 × 405 × 10^9 = 810 GFLOPs/token
- B_kv = 516 KB/token
- BW_PCIe = 64 GB/s(峰值)
- C_eff ≈ 2000 TFLOP/s
计算得 κ_crit ≈ 50,因此一旦缓存 token 超过预填充 token 的 50 倍,执行就变为内存受限。典型的 65K token 文档配 32 预填充 token 产生 κ_ratio ≈ 2000,超出 κ_crit40 倍,明确处于内存受限状态。
考虑实测的 15GB/s PCIe 带宽后,κ_crit ≈ 12,进一步确认了内存受限行为。
3. 工作负载分析
3.1 多轮对话(ShareGPT)
ShareGPT 包含 90k 对话,685k 轮次。使用 LLaMA-3.1 tokenization:
- 用户查询平均 53 token
- 模型响应平均 187 token
分布特征:
- 50% 的轮次处理少于 20 个 token,90% 少于 133 个
- 50% 的 KV 缓存超过 3.2K token,10% 超过 30K
- 50% 的轮次 κ_ratio > 100,20% 超过 1000
3.2 文档问答(NarrativeQA & FinQA)
NarrativeQA:
- 47k 问题,1,572 个叙事文本(书籍、剧本)
- 文档中位长度 57K token(范围 15K-190K)
- 问题平均 12 token
- 中位 κ_ratio = 5000(IQR 2400-11000)
FinQA:
- 7.4k 问题,801 个财务文档
- 文档中位长度 167K token(范围 60K-450K)
- 问题平均 23 token
- 中位 κ_ratio = 10000(IQR 5000-17000)
“文档 Q&A 的κ_ratio 比多轮对话高出 2 个数量级,反映了 Q&A 工作负载中文档长度显著更长。”
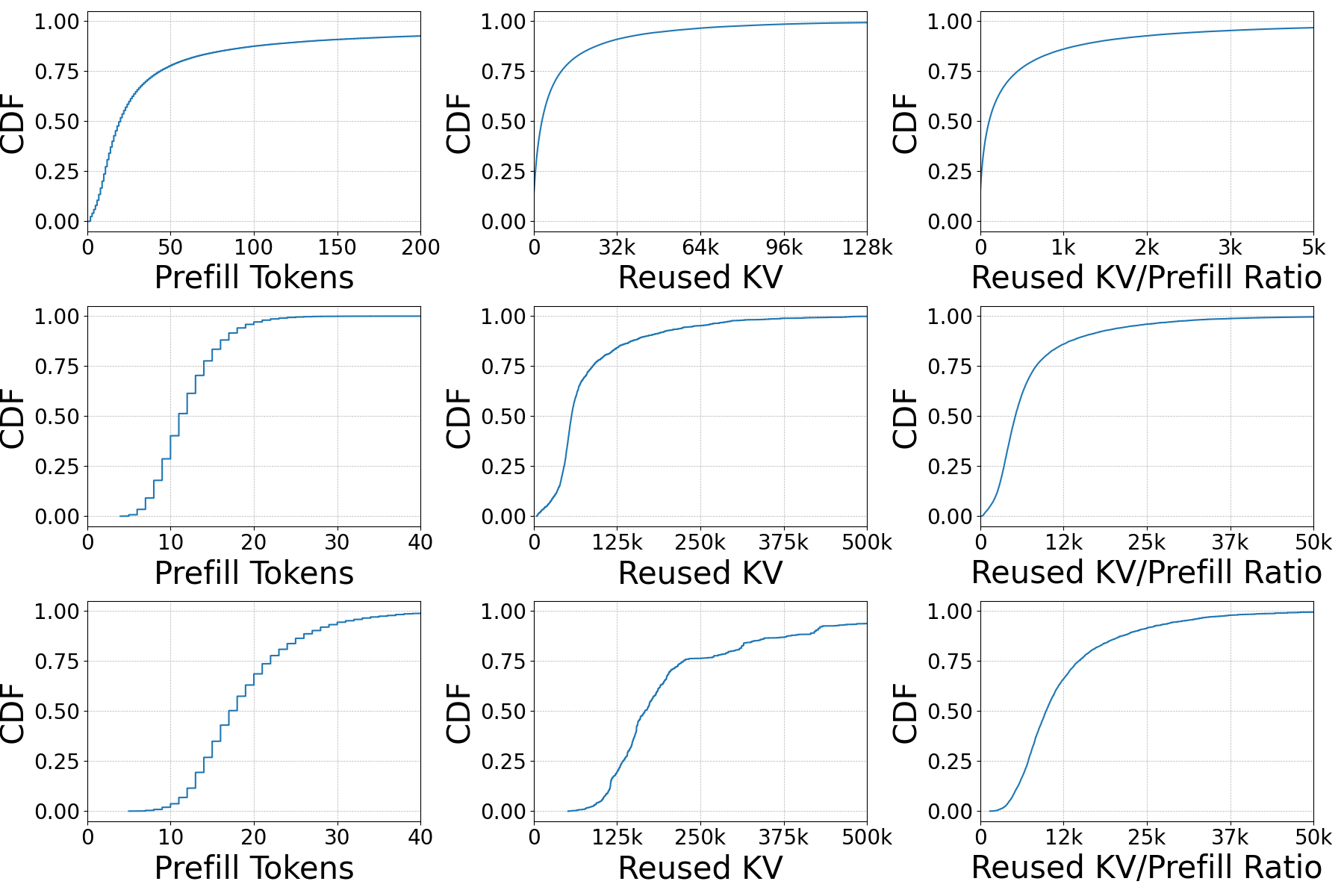 图 3:ShareGPT(顶部)、NarrativeQA(中间)和 FinQA(底部)的预填充 token(T)、复用 KV token(K)和复用 KV 与预填充 token 比率(κ_ratio)的分布。中位κ_ratio 值:ShareGPT=100,NarrativeQA=5000,FinQA=10000。(来源:原文 Figure 3)
图 3:ShareGPT(顶部)、NarrativeQA(中间)和 FinQA(底部)的预填充 token(T)、复用 KV token(K)和复用 KV 与预填充 token 比率(κ_ratio)的分布。中位κ_ratio 值:ShareGPT=100,NarrativeQA=5000,FinQA=10000。(来源:原文 Figure 3)
4. 实验评估
4.1 验证分析框架
峰值带宽分析的局限:
论文发现使用峰值硬件规格会高估 κ_crit。实测结果:
- Llama-3.1-70B:实测κ_crit = 2,估计值 14.3
- Qwen3-235B-A22B:实测κ_crit = 1,估计值 7.8
实际带宽分析的优势:
实测持续 PCIe 带宽为 15 GB/s(峰值 64 GB/s 的 23%),原因是系统瓶颈包括 CPU-GPU 内存复制开销、NUMA 效应和传输粒度。使用实测带宽重新计算κ_crit:
- Llama:3.3(接近实测的 2)
- Qwen:1.8(接近实测的 1)
这验证了分析框架,同时强调了使用经验导出带宽值的重要性。
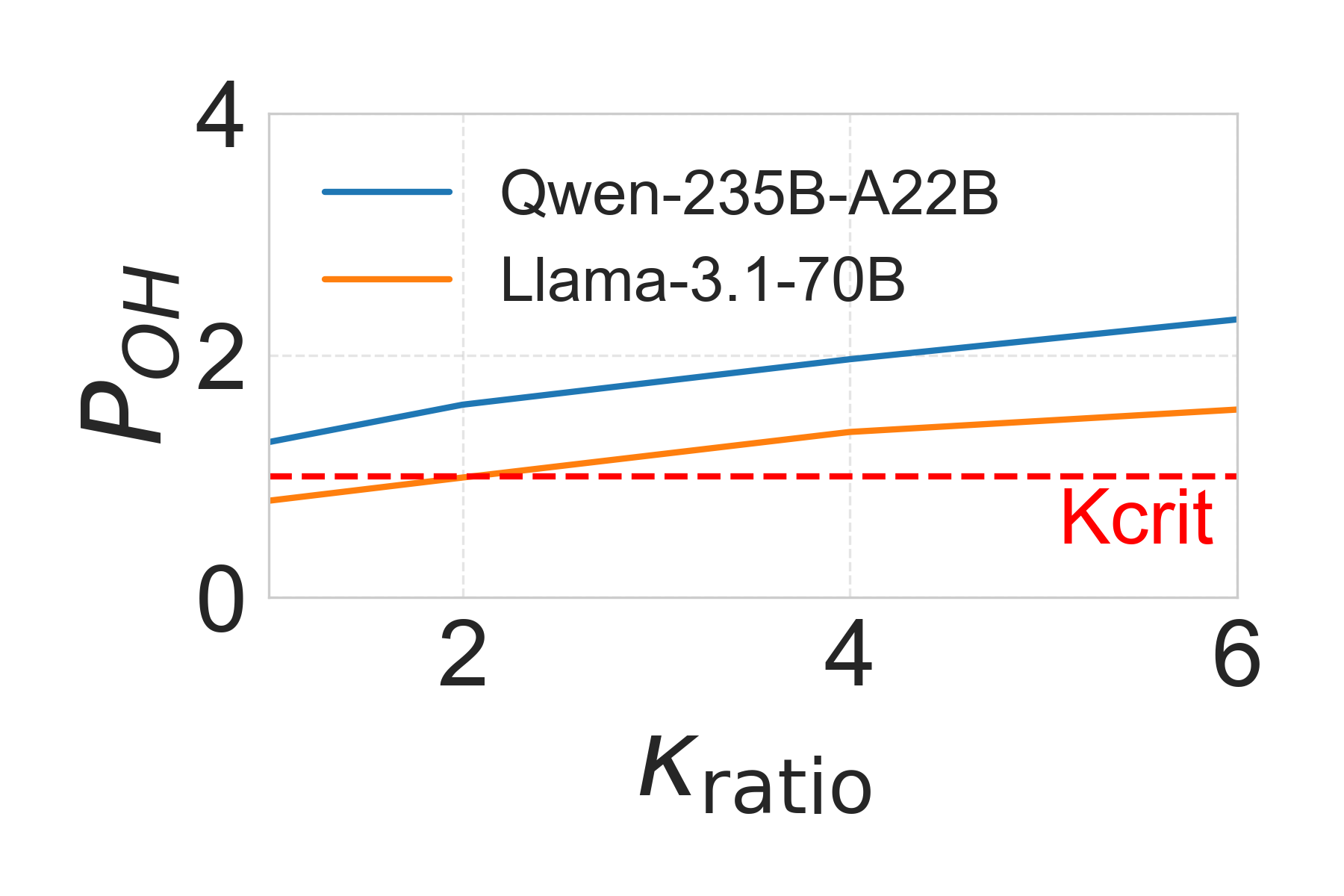 图 5:κ_crit 的实测值。PCIe 开销(POH)随κ_ratio 变化。当 POH=1 时(t_PCIe = t_GPU),执行变为内存受限。实测κ_crit 值远小于使用峰值带宽的估计值。(来源:原文 Figure 5)
图 5:κ_crit 的实测值。PCIe 开销(POH)随κ_ratio 变化。当 POH=1 时(t_PCIe = t_GPU),执行变为内存受限。实测κ_crit 值远小于使用峰值带宽的估计值。(来源:原文 Figure 5)
4.2 PCIe 开销
表 3:不同工作负载的 PCIe 开销
| 场景 | K (缓存 token) | T (预填充 token) | κ_ratio | PCIe 开销占比 |
|---|---|---|---|---|
| 小文档 | 65K | 64 | ~1000 | 99% |
| 多轮对话 | 8K | 128 | ~63 | 88% |
| 中等文档 | 6.4K | 100 | 64 | 86% |
“对于 65K+ KV token 和 64 输入 token 的小文档,Qwen 花费 99% 的时间在传输上。”
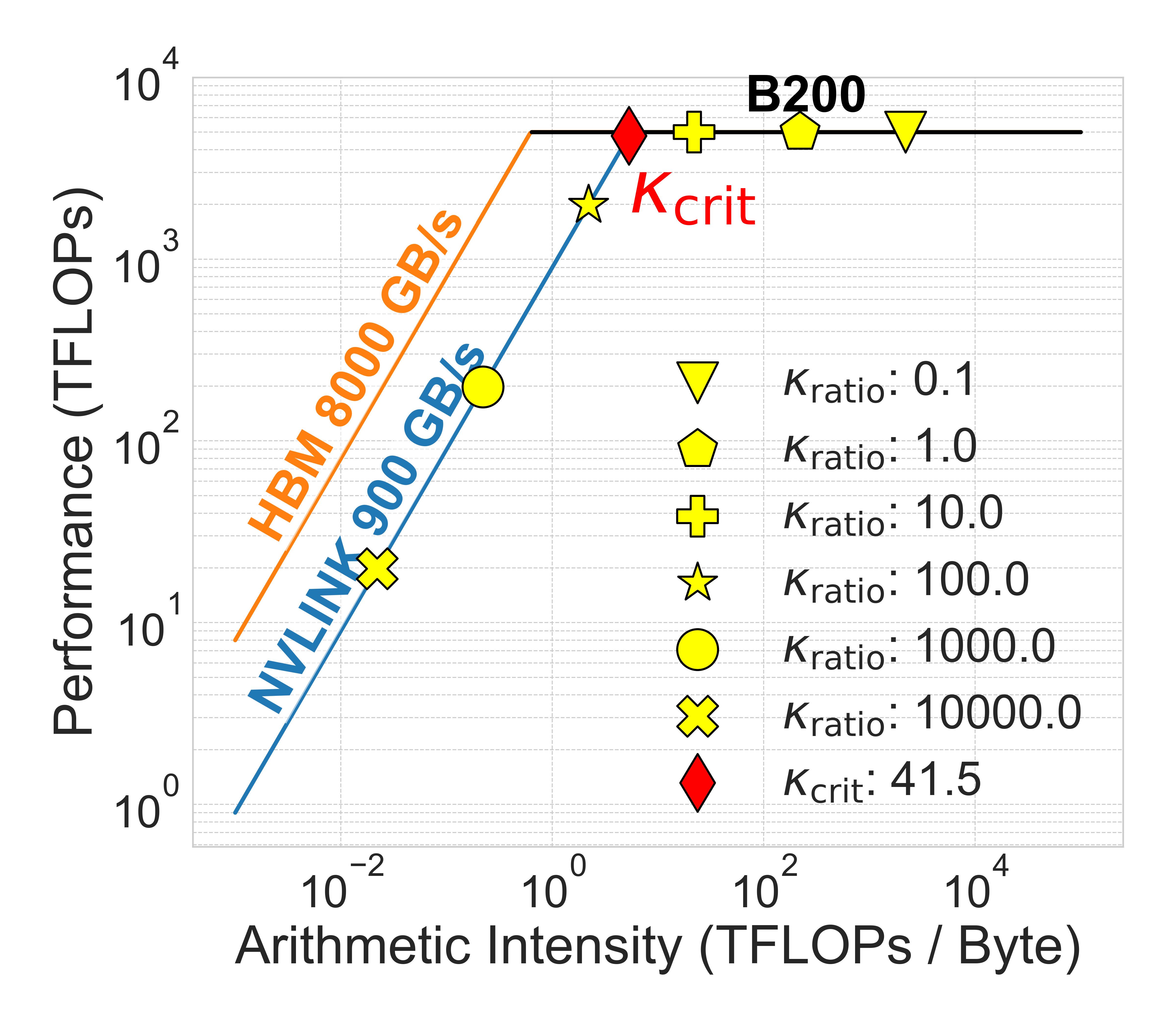 图 6:KV 缓存卸载在不同预填充 token 数量和 KV 缓存大小下的 PCIe 开销。(来源:原文 Figure 6)
图 6:KV 缓存卸载在不同预填充 token 数量和 KV 缓存大小下的 PCIe 开销。(来源:原文 Figure 6)
4.3 调度器利用率
 图 2:vLLM 调度器的迭代级调度概述。每个请求获得 token 预算,调度器在每次迭代中填充到系统范围的预算。(来源:原文 Figure 2)
图 2:vLLM 调度器的迭代级调度概述。每个请求获得 token 预算,调度器在每次迭代中填充到系统范围的预算。(来源:原文 Figure 2)
vLLM 使用迭代级调度和 token 预算来饱和 GPU 计算。然而,VRAM 容量(而非 token 预算)限制了调度器吞吐量。
表 4:ShareGPT 和 NarrativeQA 的平均每迭代调度 token 数
| RPS | ShareGPT (T_sched) | NarrativeQA (T_sched) |
|---|---|---|
| 70 | 4064 | 532 |
| 130 | 3793 | 555 |
对于 ShareGPT,平均 K=11115,T=82。使用公式计算 T_sched = 3509,与实测值一致。这确认了 VRAM 容量(而非 token 预算)限制了调度器吞吐量。
4.4 GPU 功耗与利用率
表 5:ShareGPT 和 NarrativeQA 的平均和最大 GPU 功耗
| RPS | ShareGPT 平均 (W) | ShareGPT 最大 (W) | NarrativeQA 平均 (W) | NarrativeQA 最大 (W) |
|---|---|---|---|---|
| 70 | 196 | 342 | 152 | 202 |
| 130 | 192 | 287 | 152 | 194 |
关键发现:
- GPU 仅使用最大 TDP 的 28%(ShareGPT)和 22%(NarrativeQA)
- ShareGPT 比 NarrativeQA 消耗多 29% 的功率,因为调度了更多 token
- 低 GPU 利用率对数据中心基础设施(电力、冷却、配电)有重大影响,导致每单位有用工作的成本增加
5. 系统启示
5.1 硬件优化
CPU-GPU 互连:
NVIDIA 的 Grace Blackwell 和 Grace Hopper 采用 NVLink Chip-to-Chip(C2C)互连,单向带宽 900 GB/s,比 PCIe 5.0 高 14 倍。
- Qwen3-235B-A22B 的 κ_crit 从 7.8 提升到 41.5(5.3 倍)
- DeepSeek-V3 的 κ_crit 达到 191
然而,文档 Q&A 的中位κ_ratio = 5000,即使 NVLink C2C 系统仍处于内存受限状态。
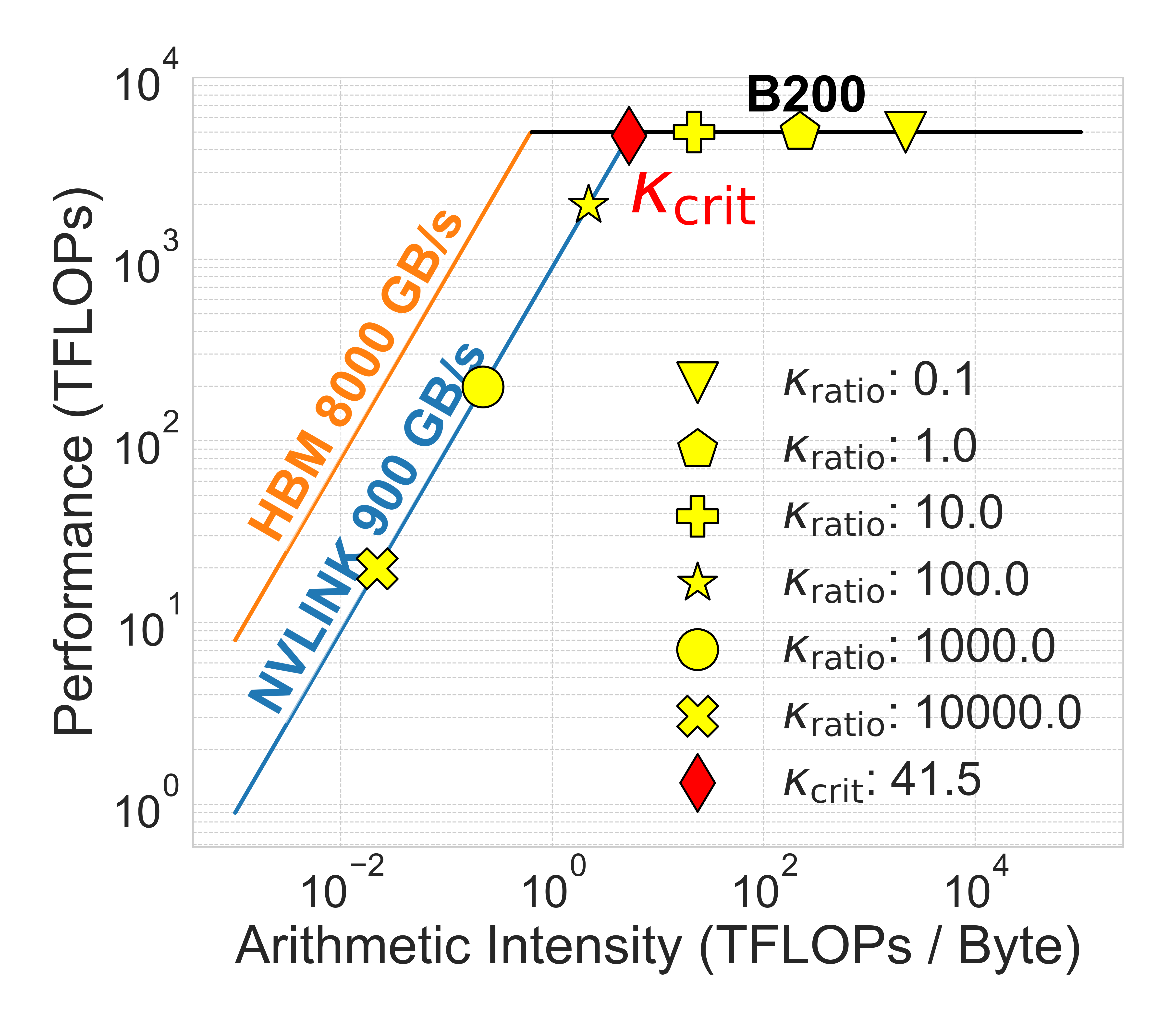 图 7:NVLink C2C 和统一 HBM 架构的 Roofline 模型。NVLink C2C 相比 PCIe 5.0 带宽提升 14 倍,κ_crit 提升 5.3 倍。统一 HBM 提供额外 9 倍改进,显著扩展计算受限区域。(来源:原文 Figure 7)
图 7:NVLink C2C 和统一 HBM 架构的 Roofline 模型。NVLink C2C 相比 PCIe 5.0 带宽提升 14 倍,κ_crit 提升 5.3 倍。统一 HBM 提供额外 9 倍改进,显著扩展计算受限区域。(来源:原文 Figure 7)
统一内存架构:
更激进的解决方案将 CPU 和 GPU die 集成到同一封装上,共享统一 HBM,消除 CPU-GPU 互连瓶颈:
- Qwen3-235B-A22B 的 κ_crit 提升到 370(比 NVLink 高 9 倍)
- DeepSeek-V3 的 κ_crit 达到 1700
这种架构下,即使是文档 Q&A 工作负载也接近计算受限状态(对于 MLA 模型)。
5.2 模型架构优化
Multi-Head Latent Attention(MLA):
MLA 通过低秩投影压缩 KV 表示。DeepSeek-V3 实现 B_kv = 70 KB/token,相比 GQA 模型的 192-328 KB/token,减少了 2.7-4.7 倍。
KV 缓存量化:
将 KV 缓存量化到更低精度(INT8、FP8、FP4)可减少 B_kv:
- INT8:2 倍减少,最小精度损失
- FP4:4 倍压缩
结合 MLA(2.7 倍),量化可产生高达 11 倍的总内存占用减少。
5.3 工作负载感知异构化
在异构集群中(Grace Hopper、H100、A100),智能路由可匹配工作负载特性与硬件能力:
- 高κ_ratio 请求(κ_ratio > 100):路由到 Grace Hopper,更高带宽减少传输开销
- 计算密集型预填充(κ_ratio < 1):路由到 H100/A100,以更低成本获得计算吞吐量
- 解码请求:继续路由到内存优化系统(如当前异构化)
电力配置:
高κ_ratio 工作负载的服务器可以功率限制在 200-300W,而不影响吞吐量(因为 PCIe 带宽而非计算限制性能)。这释放了电力预算用于更多服务器,可能通过更高并发提高总吞吐量。
5.4 利用率感知调度
传统 FIFO 调度因 VRAM 约束导致 token 预算未充分利用。改进的调度器应最大化 VRAM 约束下的计算利用率。
公平性机制:
- 老化积分:请求优先级随等待时间成比例增加
- 加权公平队列:按请求优先级而非到达顺序分配 VRAM
- 准入控制:限制并发高κ_ratio 请求以防止 VRAM 饱和
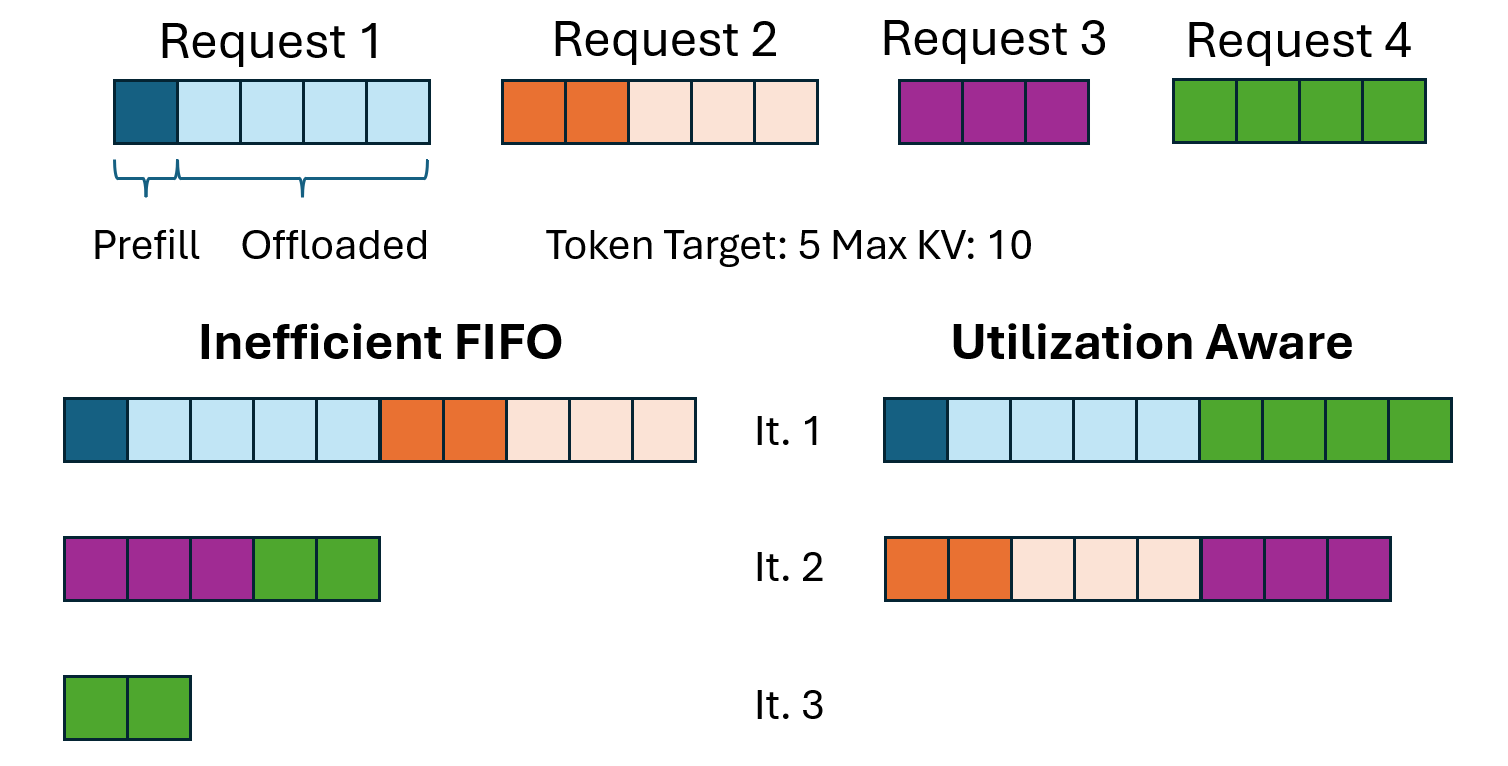 图 8:利用率感知调度示例。FIFO 调度(左)因 VRAM 约束导致 token 预算未充分利用(迭代 1 中 3/5 token)。利用率感知调度(右)通过重新排序请求饱和 token 预算(5/5 token)。(来源:原文 Figure 8)
图 8:利用率感知调度示例。FIFO 调度(左)因 VRAM 约束导致 token 预算未充分利用(迭代 1 中 3/5 token)。利用率感知调度(右)通过重新排序请求饱和 token 预算(5/5 token)。(来源:原文 Figure 8)
6. 总结与展望
本文开发了一个分析框架,展示了预填充如何因模型特性和硬件规格而变为内存受限。通过实证表征 KV 卸载,发现预填充在非常小的 κ_ratio 值下就变得内存受限,导致资源浪费和 GPU 低利用率。
主要贡献:
- 提出了 κ_crit 和 κ_ratio 的形式化分析框架
- 实证测量显示 PCIe 开销可达 99% 的执行时间,GPU 仅使用 28% TDP
- 识别了硬件(NVLink C2C、统一 HBM)、模型(MLA、量化)和调度优化的方向
未来工作:
- 实证表征 MLA 和量化技术的收益
- 完善超大上下文下的 F_pfl 模型
- 建模写入操作开销和读写竞争
“即使激进的 KV 压缩也无法消除 PCIe 瓶颈。在κ_ratio = 100-1000 的典型工作负载下,所有模型都变为带宽受限。”
参考文献
- Kwon W, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention. SOSP 2023.
- Patel et al. SplitInfer: Spatiotemporal Disaggregation of LLM Inference. 2024.
- DeepSeek-AI et al. DeepSeek-V3 Technical Report. 2025.
- Grattafiori et al. The Llama 3 Herd of Models. 2024.
- Liu et al. LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference. 2024.
- Yao et al. DistiLLM: Towards Streamlined Distillation for Large Language Models. 2025.
- Reddy et al. FinQA: A Dataset of Numerical Reasoning over Financial Data. 2024.
- Kociský et al. The NarrativeQA Reading Comprehension Challenge. 2017.
本文基于 arXiv:2601.19910 自动生成,旨在提供技术洞察和快速理解。如需引用,请参考原始论文。