Research Article
The Price Is Not Right: Neuro-Symbolic Methods Outperform VLAs on Structured Long-Horizon Manipulation Tasks
The Price Is Not Right: Neuro-Symbolic Methods Outperform VLAs on Structured Long-Horizon Manipulation Tasks
原文链接: arXiv:2602.19260 项目主页
摘要
Vision-Language-Action (VLA) 模型最近被提出作为通用机器人策略的途径,能够解释自然语言和视觉输入以生成操作动作。然而,它们在结构化、长视野操作任务上的有效性和效率仍不清楚。本文展示了微调的开放权重 VLA 模型 (π₀) 与结合 PDDL 符号规划和学习型低级控制的神经符号架构之间的直接经验比较。在 3 块 Towers of Hanoi 任务上,神经符号模型实现了 95% 的成功率,而表现最好的 VLA 仅为 34%。神经符号模型还能泛化到未见过的 4 块变体(78% 成功率),而两个 VLA 都无法完成任务。在训练期间,VLA 微调消耗的能量几乎是神经符号方法的两个数量级。
1. 问题定义
“Vision-Language-Action (VLA) models have recently been proposed as a pathway toward generalist robotic policies capable of interpreting natural language and visual inputs to generate manipulation actions. However, their effectiveness and efficiency on structured, long-horizon manipulation tasks remain unclear.”
随着 VLA 模型在机器人领域的兴起,一个关键问题尚未得到解答:这些端到端的基础模型方法在需要顺序推理的结构化长视野任务上是否真的优于传统的结构化方法?特别是,考虑到微调和部署相关的巨大计算和能源成本,这种优势是否合理?
本文通过一个受控的实验设置来回答这个问题:在 Robosuite 模拟环境中设计的 Towers of Hanoi 操作任务,用于全面基准测试多步机器人操作能力。
2. 方法框架
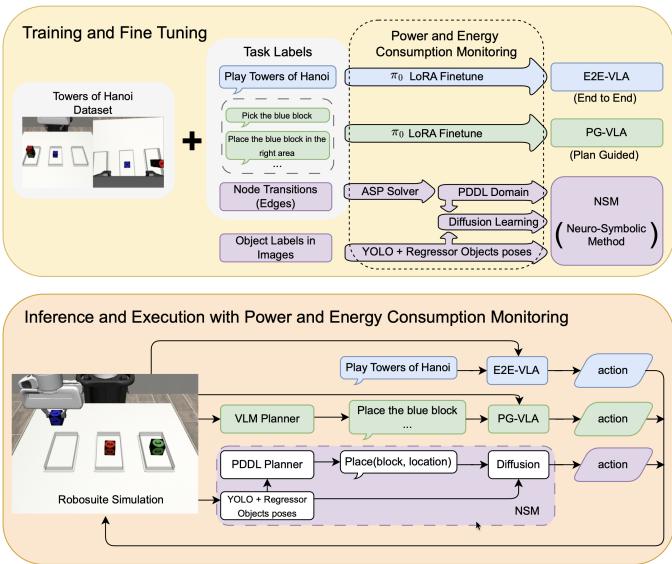 图 1:VLA 模型和神经符号模型 (NSM) 之间的实验比较概述。两者都从模拟中接收相同的感官输入。VLA 产生基于高级任务描述或规划器指导的动作,而 NSM 进行符号规划并通过学习到的策略执行。在训练和推理期间监控功率和能量。(来源:原文 Figure 1)
图 1:VLA 模型和神经符号模型 (NSM) 之间的实验比较概述。两者都从模拟中接收相同的感官输入。VLA 产生基于高级任务描述或规划器指导的动作,而 NSM 进行符号规划并通过学习到的策略执行。在训练和推理期间监控功率和能量。(来源:原文 Figure 1)
本文比较了三种方法:
2.1 End-to-End VLA (E2E-VLA)
“A vision-language-action model fine-tuned on the training datasets using a single high-level command, ‘Play Towers of Hanoi’, applied at every frame of the training episodes. This model learns the task as a monolithic sequence without explicit decomposition into sub-tasks and does not use any external planning mechanism.”
E2E-VLA 使用单一高级命令”Play Towers of Hanoi”进行微调,将整个任务作为单一序列学习,没有明确的子任务分解,也不使用任何外部规划机制。
2.2 Planner-Guided VLA (PG-VLA)
“A vision-language-action model fine-tuned on our datasets using structured subtask commands, in combination with an external planner. This approach decomposes the overall task into smaller natural language sub-goals, enabling stepwise guidance during execution.”
PG-VLA 使用结构化的子任务命令进行微调,结合外部规划器。这种方法将整体任务分解为更小的自然语言子目标,在执行期间实现逐步指导。
2.3 Neuro-Symbolic Model (NSM)
“A baseline method that learns both high-level symbolic planning and low-level continuous control directly from demonstrations. The NSM extracts abstract operators and builds a PDDL domain from a small number of demonstrations, executing the task by sequencing learned neural policies according to the planned operator sequence.”
NSM 直接从演示中学习高级符号规划和低级连续控制。它从少量演示中提取抽象操作符并构建 PDDL 域,根据规划的操作符序列执行学习到的神经策略。
3. 核心模块
3.1 VLA 架构
VLA 模型使用 π₀ (OpenPi) 作为代表性的开放权重 VLA 模型,采用以下配置:
- 视觉 - 语言主干: PaliGemma 2B LoRA
- 动作头: Gemma 300M LoRA
- 微调方法: LoRA 微调 30k 步
- 训练数据: 300 集 Towers of Hanoi 演示
3.2 神经符号架构
NSM 采用分层架构,结合符号规划和神经控制:
“Neuro-symbolic architectures combine symbolic reasoning with neural control. A planner solves a STRIPS task to produce a plan, where each operator is refined into a neural skill. Each skill interacts with the environment to realize the operator’s effects, transitioning the system from a state to a new state.”
符号抽象: 从原始演示轨迹中提取节点转换,形成表示抽象状态的图。使用基于 ASP 的求解器推断 PDDL 形式的符号域。
目标检测: 训练 YOLOv8 边界框检测器结合轻量级梯度提升回归器,从两个摄像头视图(静态摄像头和腕部安装摄像头)估计 3D 物体姿态。
训练控制: 每个操作符关联一个神经策略,使用扩散模型训练,捕获多模态动作分布并提高鲁棒性。
 图 2:数据集中的示例观测。左:代理视图 RGB 图像。右:腕部安装摄像头 RGB 图像。(来源:原文 Figure 2)
图 2:数据集中的示例观测。左:代理视图 RGB 图像。右:腕部安装摄像头 RGB 图像。(来源:原文 Figure 2)
4. 实验设置
4.1 硬件配置
所有微调、训练、推理和实验均在单个 NVIDIA GeForce RTX 4090(24GB 内存)上执行。
- GPU 功耗使用 Weights & Biases 测量
- CPU 功耗通过访问 RAPL 日志测量
- 空闲 GPU 功耗平均约 25W,空闲 CPU 功耗约 2.5W
4.2 任务环境
实验在三个不同的任务环境中进行:
- Individual Move: 基本的抓取和放置任务,代理必须将单个块放置到另一个指定块或区域上
- 3-Block Towers of Hanoi: 三块 Towers of Hanoi 任务,需要将塔从左平台重建到右平台,同时遵守较大的块永远不能放在较小块上的约束
- 4-Block Towers of Hanoi: 最具挑战性的变体,四块 Towers of Hanoi 任务
4.3 训练数据
VLA 训练数据集: 300 集演示
- 前 150 集:完整的 Towers of Hanoi 运行,随机选择 4 个可能块中的 3 个
- 后 150 集:从块的随机有效配置开始,同时遵守任务规则
NSM 训练数据集: 仅 50 集随机采样的 Stacking 任务(抓取和放置对)演示
- 关键:NSM 在演示期间从未直接观察 Towers of Hanoi 解析,而是从这些更简单的堆叠演示中推断规则和符号规划域
4.4 评估指标
任务指标:
- 成功率(主要指标)
- 任务进展率(完成的子任务百分比)
- 泛化能力(4 块变体)
能源指标:
- 训练期间:总 GPU 能量消耗、平均 GPU 功率、平均 CPU 利用率、总训练时间
- 执行期间:平均 GPU 和 CPU 利用率、平均执行时间、每集能量消耗
5. 实验结果
5.1 能源消耗
训练和微调
| 指标 | E2E-VLA | PG-VLA | NSM |
|---|---|---|---|
| 训练时间 | 1d 16h 26m | 1d 15h 42m | 34m |
| GPU 平均功率 (W) | 423.6 | 409.1 | 316.5 |
| GPU 能量 (MJ) | 61.7 | 58.5 | 0.65 |
| CPU 平均功率 (W) | 46.6 | 44.7 | 97.7 |
| CPU 能量 (MJ) | 6.8 | 6.4 | 0.2 |
| 总能量 (MJ) | 68.5 | 64.9 | 0.85 |
关键发现: VLA LoRA 微调消耗的能量几乎是 NSM 训练的两个数量级(68.5 MJ vs 0.85 MJ)。每个 VLA 微调需要超过 1.5 天,而 NSM 在 34 分钟内完成训练。
推理和执行
| 设置 | 指标 | E2E-VLA | PG-VLA | NSM |
|---|---|---|---|---|
| 所有任务 | GPU 功率 (W) | 72.4 | 70.8 | 0 |
| CPU 功率 (W) | 42.8 | 43.2 | 19.4 | |
| 总功率 (W) | 115.2 | 114.0 | 19.4 | |
| Individual Move | 成功率 (%) | 87.0 | 59.6 | 99.0 |
| 持续时间 (s) | 13.8 | 12.4 | 6.3 | |
| 能量 (kJ) | 1.59 | 1.41 | 0.12 | |
| 3-Block Hanoi | 成功率 (%) | 34.0 | 0.0 | 95.0 |
| 进展率 (%) | 49.6 | 23.9 | 97.3 | |
| 每集能量 (kJ) | 7.96 | 6.94 | 0.83 | |
| 4-Block Hanoi | 成功率 (%) | 0.0 | 0.0 | 78.0 |
| 进展率 (%) | 2.5 | 3.6 | 84.4 | |
| 每集能量 (kJ) | 5.77 | 4.96 | 1.44 |
关键发现:
- NSM 在所有任务上的成功率都显著高于 VLA 模型
- VLA 需要 GPU 支持的推理,而 NSM 不需要
- VLA 的总功率超过 NSM 的 5 倍,每集能量消耗大约是一个数量级
- 在 4 块 Hanoi 任务上,只有 NSM 能够完成任务(78% 成功率)
5.2 VLM 规划器比较
本文还评估了三个 VLM 作为规划器的能力:
| 指标 | GPT-5 | Qwen (7B) | PaLI-Gemma (3B) |
|---|---|---|---|
| 最优计划 (%) | 84 | 0 | 0 |
| 次优计划 (%) | 0 | 0 | 0 |
| 无效计划 (%) | 16 | 100 | 100 |
| 延迟 (s) | 63.1 | 1.83 | 0.22 |
| 每查询总能量 (J) | - | 269.2 | 28.8 |
“These results indicate that VLMs are not reliable and energy-efficient planners. This is consistent with Kambhampati’s finding that large language models cannot reliably plan.”
GPT-5 在生成有效和最优计划方面远优于 Qwen 和 PaliGemma,但由于其规模更大,预计能源消耗也更大。
6. 优点与局限
优点
神经符号方法的优势:
- 更高的任务成功率: 在 3 块 Hanoi 任务上达到 95% 成功率,而 VLA 最佳为 34%
- 更好的泛化能力: 能够泛化到未见过的 4 块变体(78% 成功率),而 VLA 完全失败
- 显著的能源效率: 训练能量消耗减少近两个数量级(0.85 MJ vs 68.5 MJ)
- 更快的训练速度: 34 分钟 vs 1.5 天
- 更低的推理成本: 不需要 GPU 支持的推理
- 数据效率: 仅使用 50 集演示(vs VLA 的 300 集)
局限
神经符号方法的限制:
- 适用范围: 主要适用于具有明确程序约束的结构化任务域
- 符号抽象学习: 需要从演示中学习符号抽象,可能在更开放的任务域中更具挑战性
- 对象检测依赖: 依赖 YOLOv8 检测器进行对象姿态估计,可能受检测质量影响
VLA 方法的限制:
- 能源密集型: 微调和推理都需要大量能源
- 泛化能力差: 难以泛化到训练分布外的任务变体
- 长视野规划困难: 在需要顺序推理的任务上表现不佳
- 训练时间长: 需要大量时间和计算资源进行微调
7. 总结
“The neuro-symbolic model outperforms the fine-tuned VLAs on the Towers of Hanoi task in both task success and energy consumption. It also generalizes to the 4-block variant despite not being trained on it, demonstrating robustness on structured, multi-step manipulation.”
本文展示了在结构化长视野机器人操作任务上,神经符号方法相对于端到端 VLA 模型的显著优势。关键发现包括:
- 在 3 块 Towers of Hanoi 基准测试中,神经符号方法实现了 95% 的成功率,而表现最好的 VLA 仅为 34%
- 神经符号模型在训练期间消耗的能量几乎少两个数量级
- 神经符号模型能够泛化到未见过的 4 块变体(78% 成功率),而两个 VLA 都无法完成任何一集
“For manipulation tasks governed by explicit procedural constraints, incorporating symbolic structure can yield substantial advantages in reliability, data efficiency, and energy consumption.”
这些结果强调了在具有明确程序约束的操作任务中,结合符号结构可以在可靠性、数据效率和能源消耗方面带来显著优势。
参考文献
-
Duggan T, Lorang P, Lu H, Scheutz M. The Price Is Not Right: Neuro-Symbolic Methods Outperform VLAs on Structured Long-Horizon Manipulation Tasks with Significantly Lower Energy Consumption. arXiv:2602.19260, 2026.
-
Lorang P, Lu H, Huemer J, Zips P, Scheutz M. Few-shot neuro-symbolic imitation learning for long-horizon planning and acting. arXiv:2508.21501, 2025.
-
Black K, et al. π₀: A vision-language-action flow model for general robot control. arXiv:2410.24164, 2024.
-
Kim MJ, et al. OpenVLA: An open-source vision-language-action model. arXiv:2406.09246, 2024.
-
Kambhampati S, et al. LLMs can’t plan, but can help planning in LLM-modulo frameworks. 2024.